|
| Crowd4D: Scene-Aware Monocular 4D Crowd Reconstruction |
ICML, 2026  Code Code |
| Recovering scene-consistent 4D crowd motion from monocular video in large-scale scenes remains challenging due to severe depth ambiguity and complex scene geometry. Existing monocular crowd reconstruction methods typically rely on single-plane assumptions, leading to unreliable metric scale and spatial drift under complex terrain. We propose Crowd4D, the first scene-aware 4D crowd reconstruction framework that jointly optimizes the crowd and scene from a monocular RGB video in large-scale scenes. Extensive experiments demonstrate that Crowd4D outperforms existing state-of-the-art methods and enables robust monocular 4D crowd reconstruction in complex, large-scale real-world scenes. |
|
 |
| CG-Floor: Centroid-Guided Diffusion for Large-Scale Floorplan Generation |
| CVPR, 2026 Code |
| Large-scale floorplan generation is critical for virtual space planning and architectural simulation. Although existing methods have shown success in generating small-scale floorplans with simple room shapes, they struggle to handle the complex room connections and irregular room shapes that arise in large-scale floorplans. In this paper, we propose CG-Floor, a centroid-guided hierarchical framework that explicitly decouples topology and geometry to address these issues. It also supports 3D floorplan conversion and editing. |
|
 |
| MIFE: A Multimodal VR Immersive Training System for Fire Escape |
| IEEE VR, 2026 |
| While virtual reality (VR) technologies have demonstrated potential in safety education, the number of interaction modalities they offer is mostly limited to 3 to 5 types, and they heavily rely on controllers that abstract actions into button presses, limiting immersion and skill transfer. In this paper, we propose the MIFE system, which designs 8 distinct interaction modalities along with a real-time dynamic fire spread simulation to further improve immersion, allowing trainees to perceive the fire scene and efficiently master key escape skills through vision, auditory, olfactory, etc. |
|
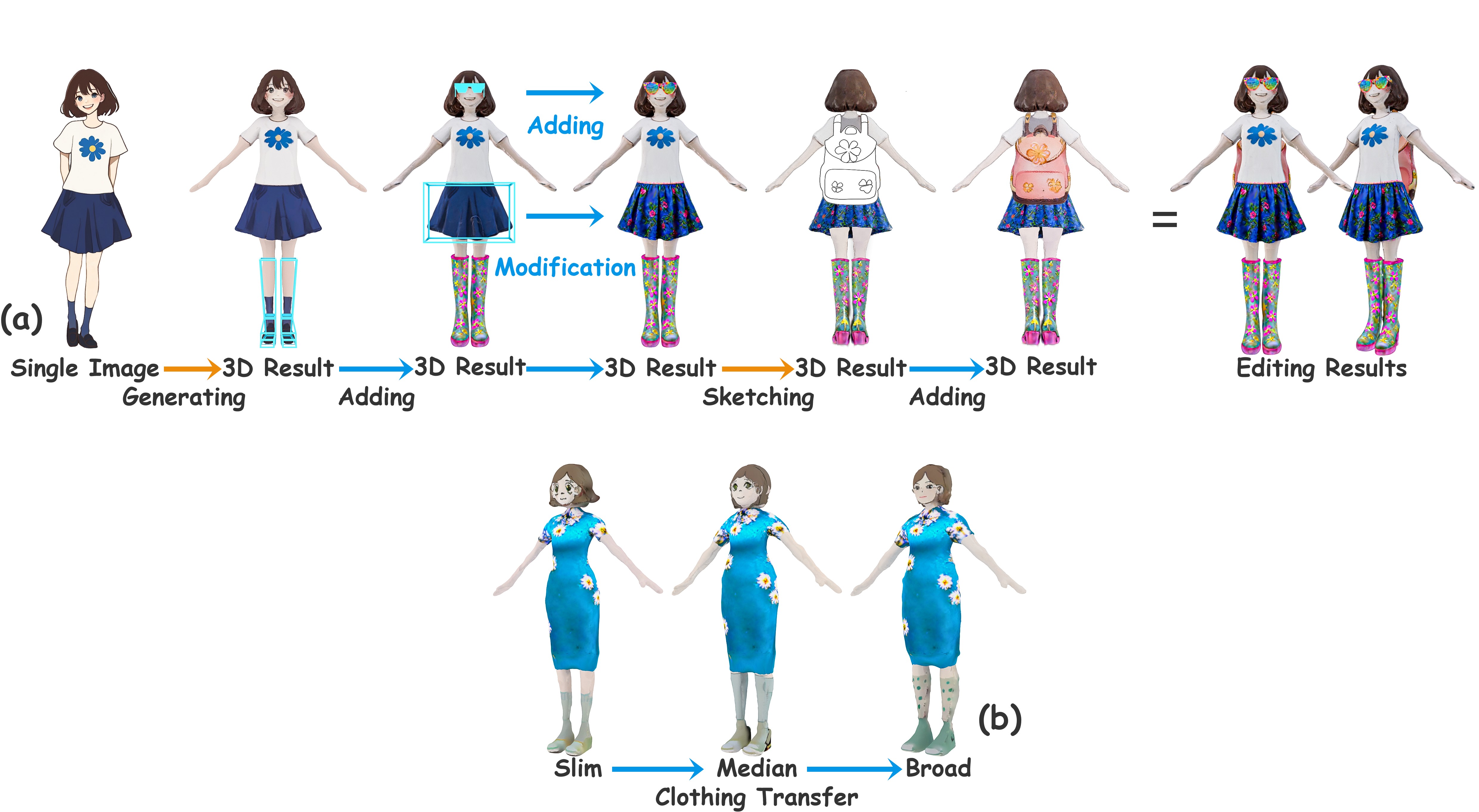 |
| InterCoser: Interactive 3D Character Creation with Disentangled Fine-Grained Features |
| AAAI, 2025, Oral Code |
| This paper aims to interactively generate and edit disentangled 3D characters based on precise user instructions. Existing methods generate and edit 3D characters via rough and simple editing guidance and entangled representations, making it difficult to achieve precise and comprehensive control over fine-grained local editing and free clothing transfer for characters. In this paper, we propose a novel user-interactive approach for disentangled 3D character creation. |
|
 |
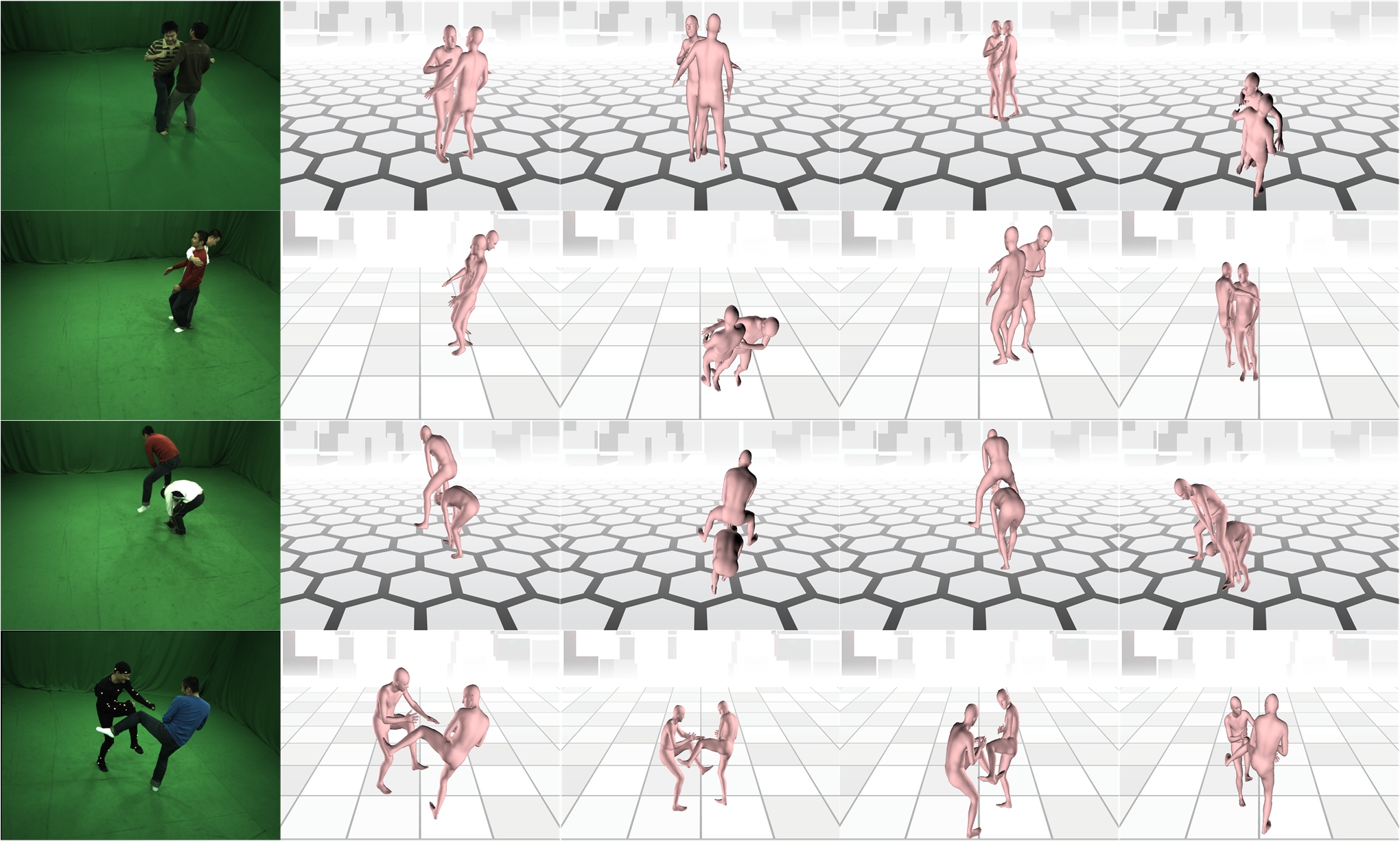
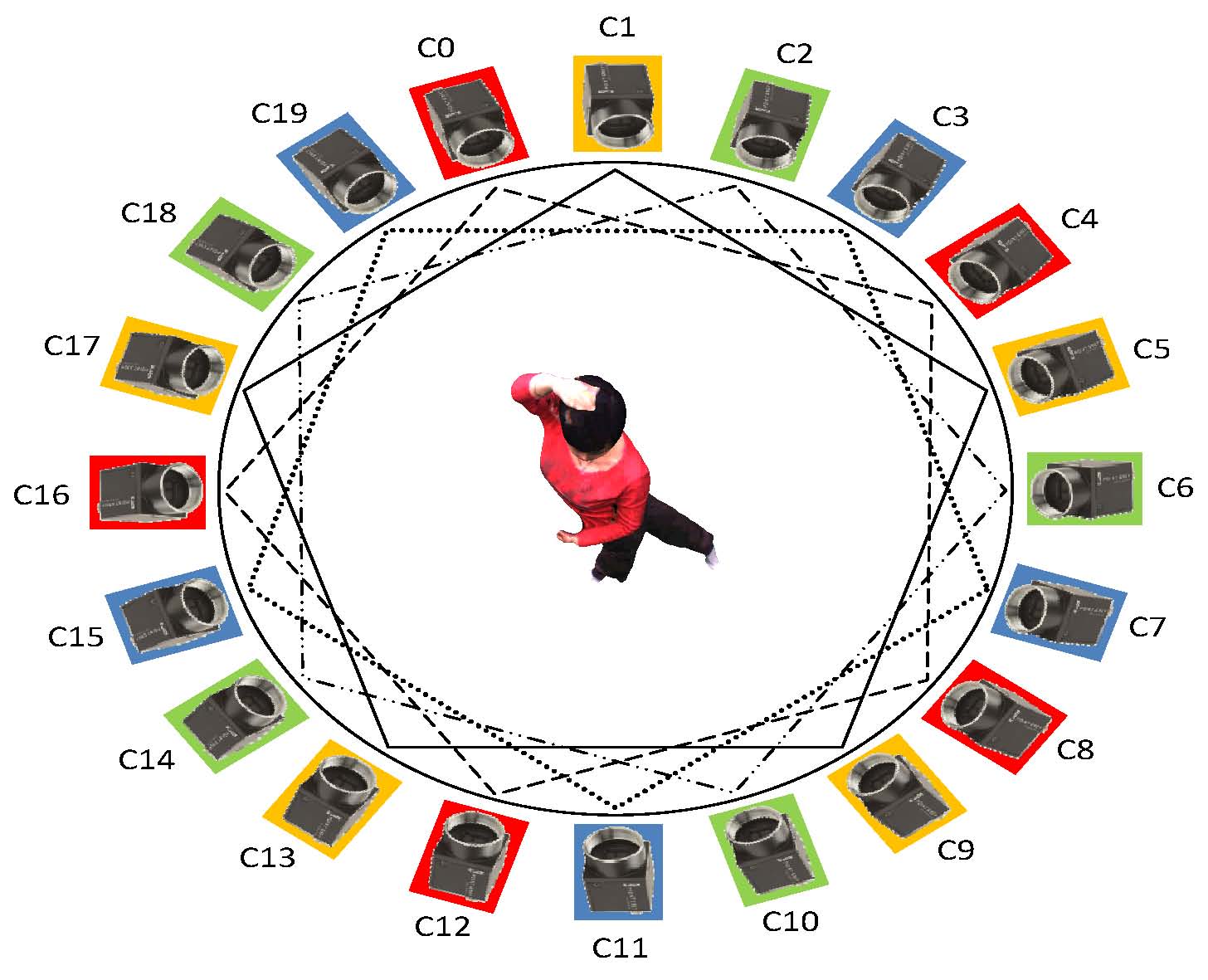
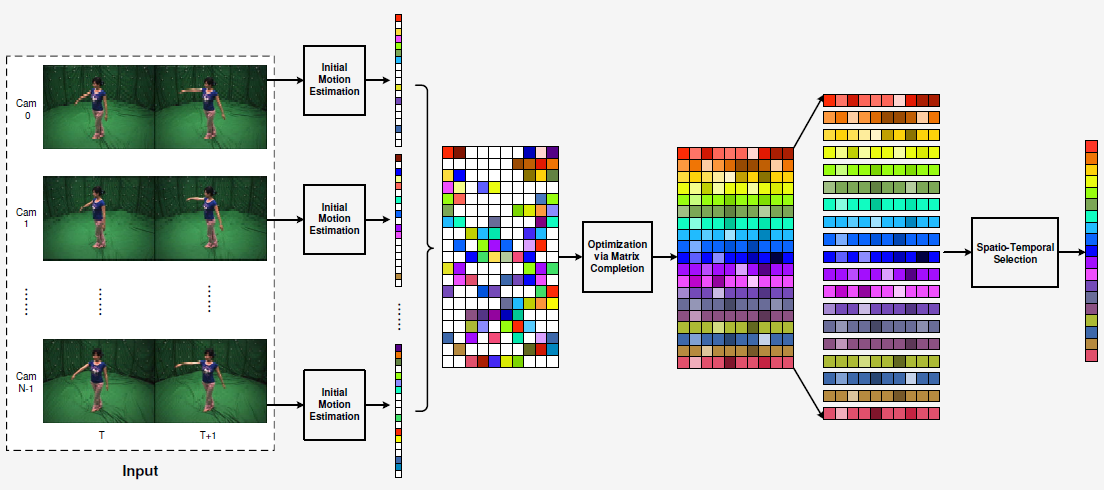
| DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video |
| IEEE TPAMI, 2025 Code |
| 3D reconstruction of dynamic crowds in large scenes has become increasingly important for applications such as city surveillance and crowd analysis. However, current works attempt to reconstruct 3D crowds from a static image, causing a lack of temporal consistency and inability to alleviate the typical impact caused by occlusions. In this paper, we propose DyCrowd, the first framework for spatio-temporally consistent 3D reconstruction of hundreds of individuals' poses, positions and shapes from a large-scene video. |
|
 |
| RESCUE: Crowd Evacuation Simulation via Controlling SDM-United Characters |
| ICCV, 2025, Highlight Code |
| Crowd evacuation simulation is critical for enhancing public safety, and demanded for realistic virtual environments. However, existing methods fail to generate reasonable, personalized and real-time evacuation motions. In this paper, aligned with the sensory-decision-motor (SDM) flow of the human brain, we propose a real-time 3D crowd evacuation simulation framework that integrates a 3D-adaptive SFM (Social Force Model) Decision Mechanism and a Personalized Gait Control Motor. This framework allows multiple agents to move in parallel and is suitable for various scenarios, with dynamic crowd awareness. Additionally, we introduce Part-level Force Visualization to assist in evacuation analysis. |
|
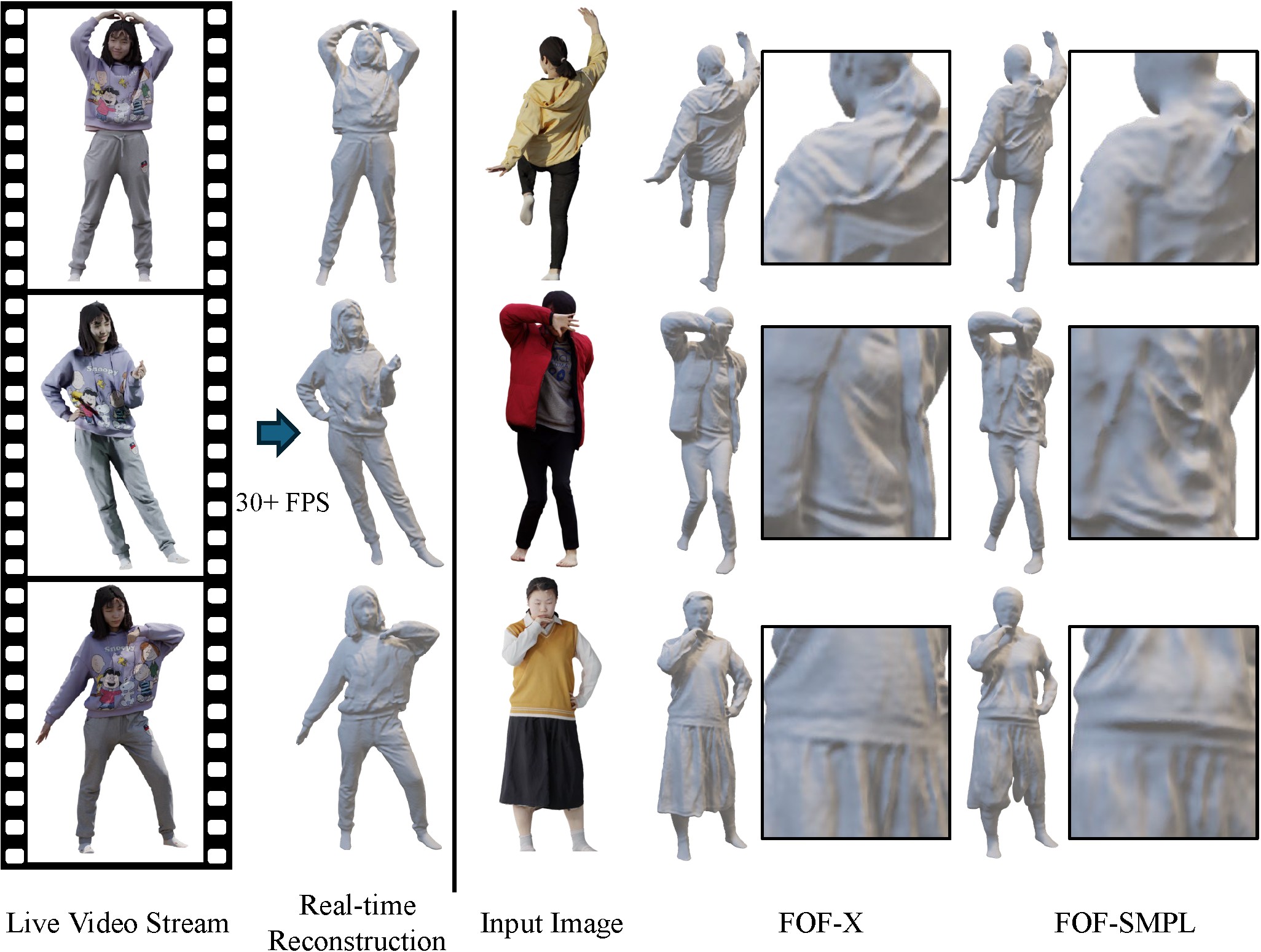 |
| FOF-X: Towards Real-time Detailed Human Reconstruction from a Single Image |
| IEEE TMM, 2025 Code |
| We extend FOF by: 1) designing a new reconstruction framework greatly mitigating the performance degradation caused by texture and lighting effects; 2) proposing a robust mesh-to-FOF conversion algorithm with an automaton-based discontinuity matcher to enable real-time execution and significantly improve the system's robustness when facing challenging poses; and 3) proposing a FOF-to-mesh algorithm with a Laplacian coordinate constraint for greater robustness and fidelity. |
|
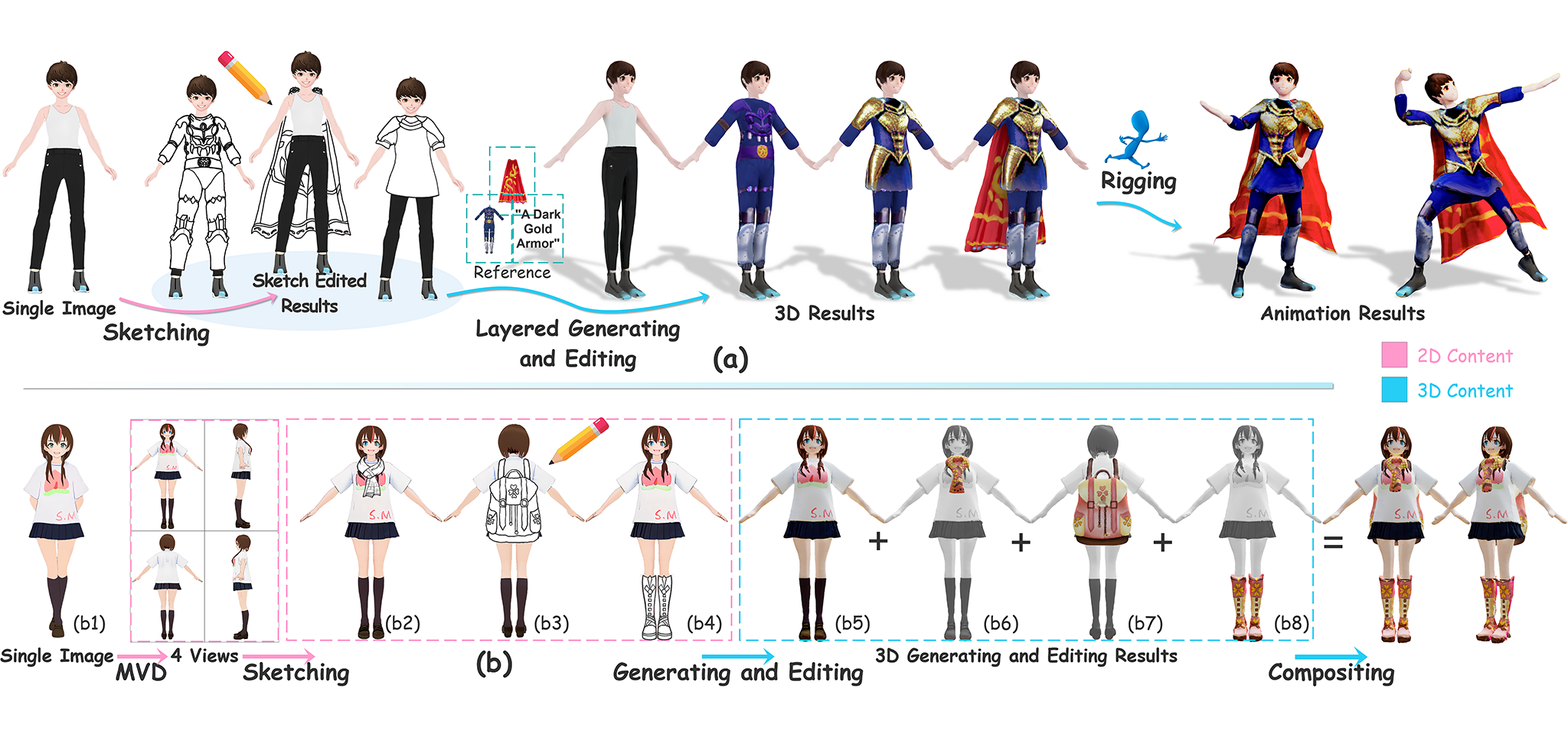 |
| DreamCoser: Controllable Layered 3D Character Generation and Editing |
| SIGGRAPH Asia 2025 Technical CommunicationsCode |
| This paper aims to controllably generate and edit layered 3D characters based on hand-drawing. To achieve controllable generation and part-level editing of high-quality 3D characters with changeable clothing, we propose an innovative layered 3D character generation and editing method based on sketches. |
|
 |
| LoGAvatar: Local Gaussian Splatting for Human Avatar Modeling from Monocular Video |
| CAD, 2025 Code |
| Avatar reconstruction from monocular videos plays a pivotal role in various virtual and augmented reality applications. However, due to the independent nature of GS primitives, existing approaches often struggle to capture high-fidelity details and lack the ability to edit the reconstructed avatars effectively. In this paper, we propose Local Gaussian Splatting Avatar (LoGAvatar), a novel framework designed to enhance both geometry and texture modeling and editing of human avatars. |
|
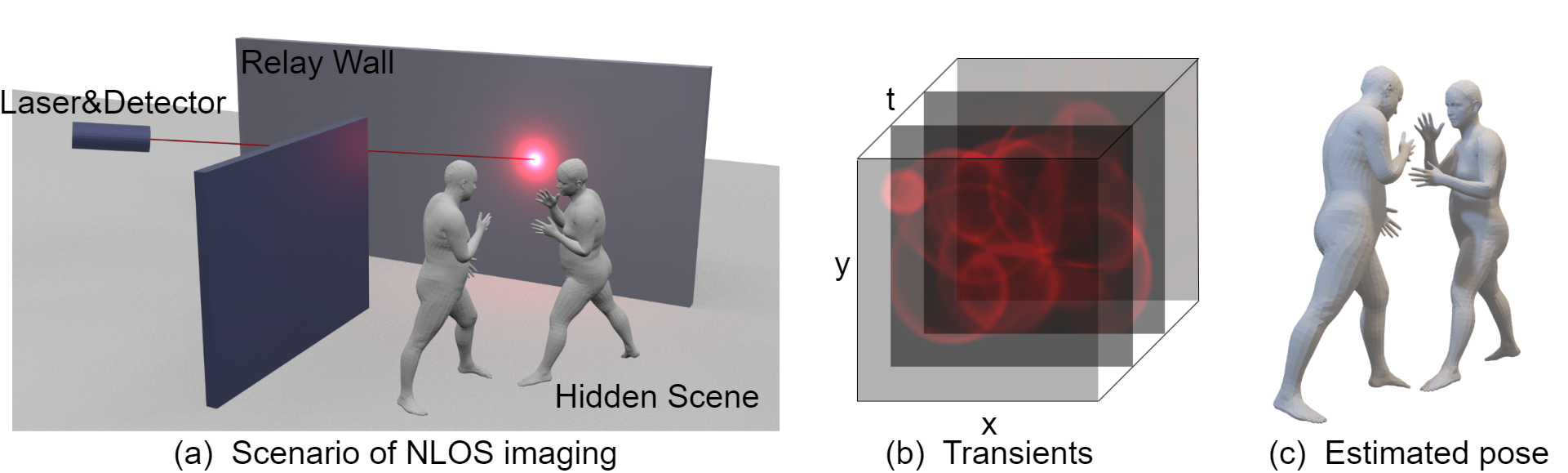 |
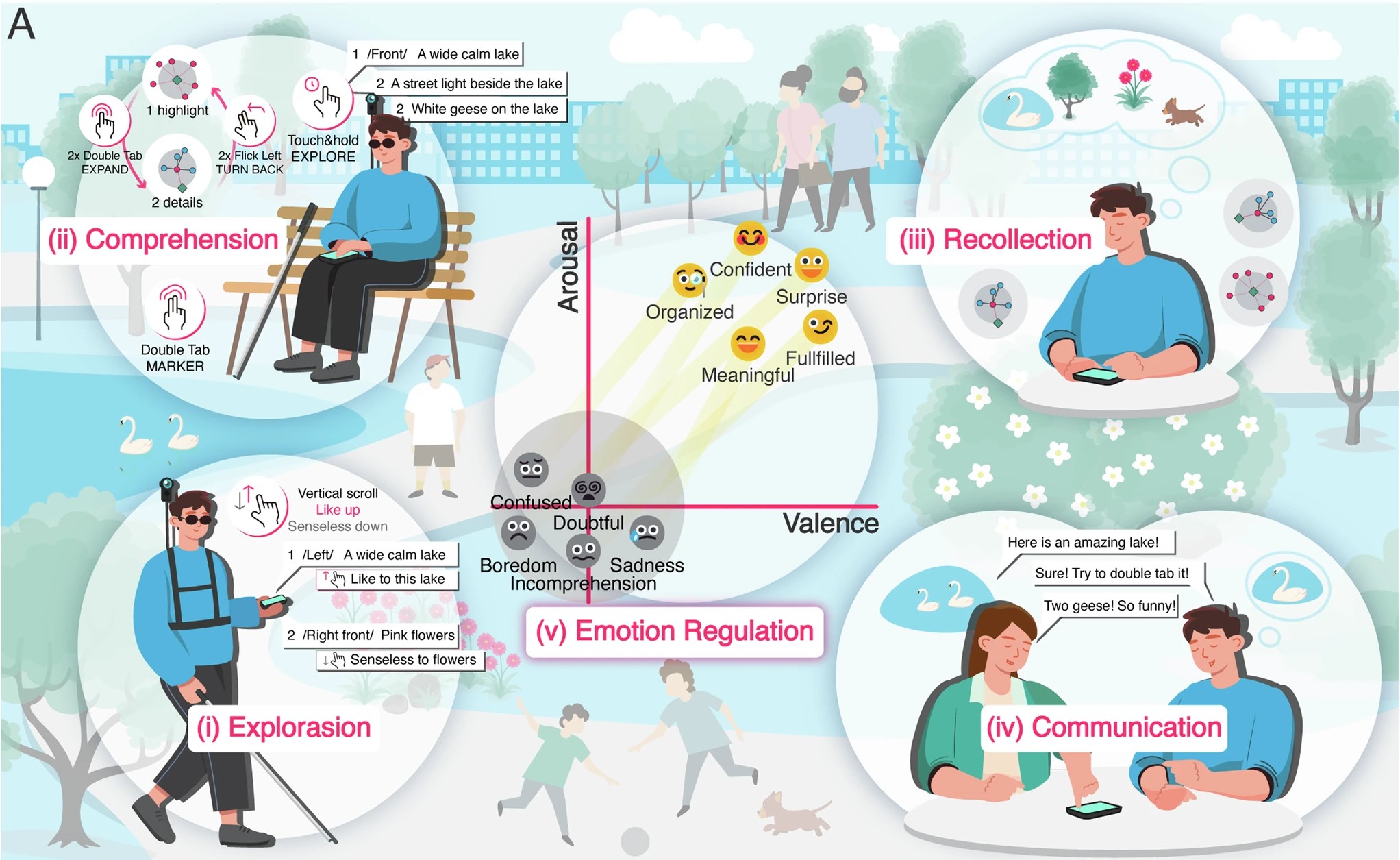
| Non-Line-of-Sight Multi-Person Pose Sensing |
| Optics Express, 2025 Dataset Editors' Pick |
| In the fields of anti-terrorism and emergency rescue, human pose sensing under non-line-of-sight (NLOS) conditions plays a critical role in enabling informed decision-making and effective response. In this paper, we propose the first method that enables adaptive multi-person pose sensing in NLOS environments. The simulation pipeline we developed for constructing the multi-person NLOS dataset and the real-world data captured by our system provide valuable resources for advancing research in this field. |
|
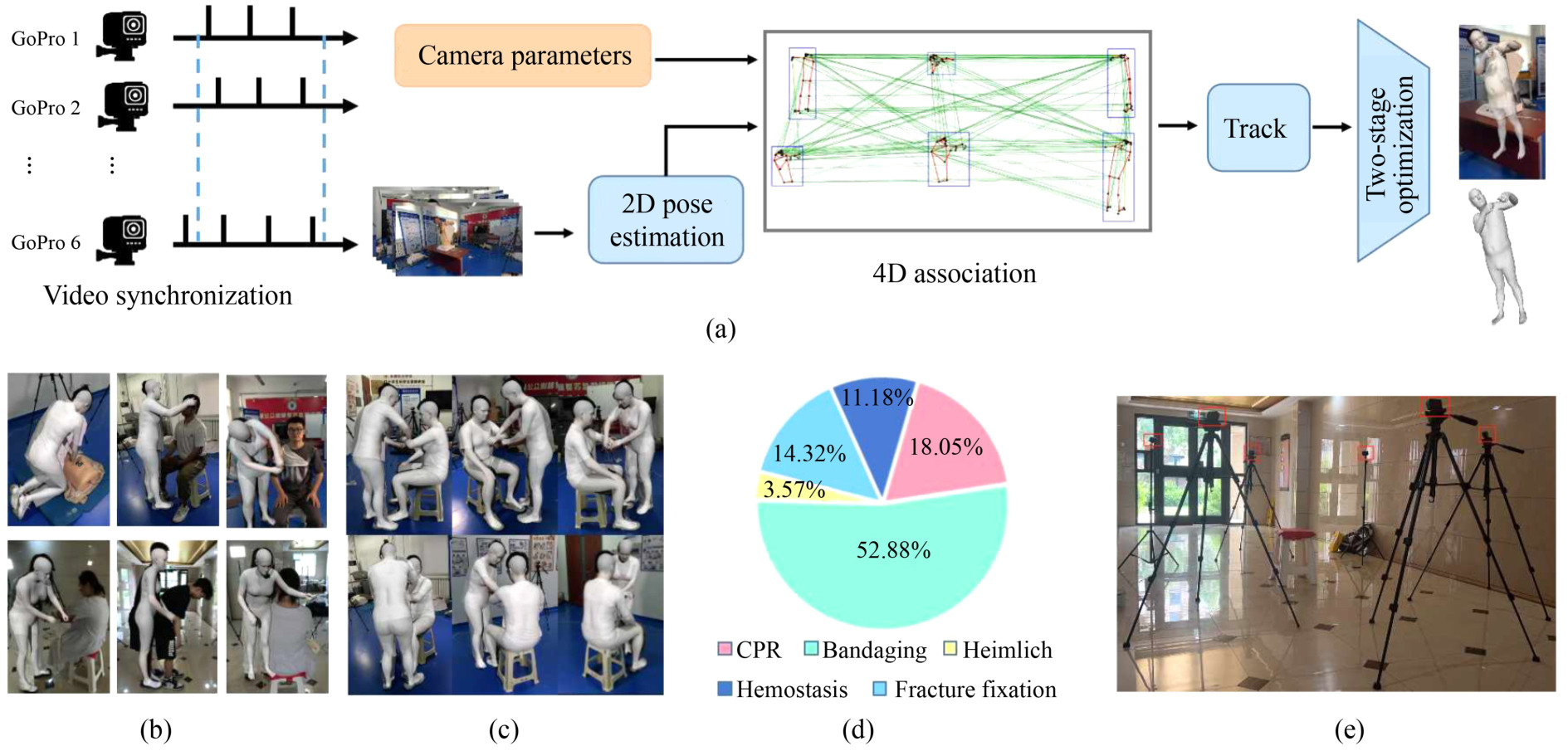 |
| EMP3D: An Emergency Medical Procedures 3D Dataset with Pose and Shape |
| Frontiers of Computer Science, 2025 Dataset |
| Emergency Medical Services play a critical role in acute emergencies, yet their effectiveness is often limited by professional complexities. Existing datasets for medical movement analysis mainly focus on basic patient actions like lying and standing, and lack 3D poses. We propose EMP3D, a new dataset capturing the intricate movements of rescuers during emergency procedures with 3D poses and shapes. This dataset will help enhance emergency response training and improve rescue skills. |
|
 |
|
 |
| SpeechAct: Towards Generating Whole-body Motion from Speech |
| IEEE TVCG, 2025 Code |
| In this paper, we introduce a novel method, named SpeechAct, based on a hybrid point representation and contrastive motion learning to boost realism and diversity in whole-body motion generation from speech. Our method can be generalized to other languages, and the generated motion can be used to animate reconstructed avatars. |
|
 |
| Real-time 3D Human Reconstruction and Rendering System from a Single RGB Camera |
| SIGGRAPH Asia 2024 Technical Communications |
| Transforming 2D human images into 3D appearance is essential for immersive communication. In this paper, we introduce a low-cost real-time 3D human reconstruction and rendering system with a single RGB camera at 28+ FPS, which guarantees both real-time computing speed and realistic rendering results. It can be applied to 3D holographic displays and virtual reality environments. |
|
 |
| DualAvatar: Robust Gaussian Splatting Avatar with Dual Representation |
| SIGGRAPH Asia Poster 2024 |
| Transforming 2D human images into 3D appearance is essential for immersive communication. In this paper, we introduce a low-cost real-time 3D human reconstruction and rendering system with a single RGB camera at 28+ FPS, which guarantees both real-time computing speed and realistic rendering results. It can be applied to 3D holographic displays and virtual reality environments. |
|
 |
| R²Human: Real-Time 3D Human Appearance Rendering from a Single Image |
| ISMAR, 2024 Code |
| Reconstructing 3D human appearance from a single image is crucial for achieving holographic communication and immersive social experiences. However, this remains a challenge for existing methods, which typically rely on multi-camera setups or are limited to offline operations. In this work, we propose R²Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. |
|
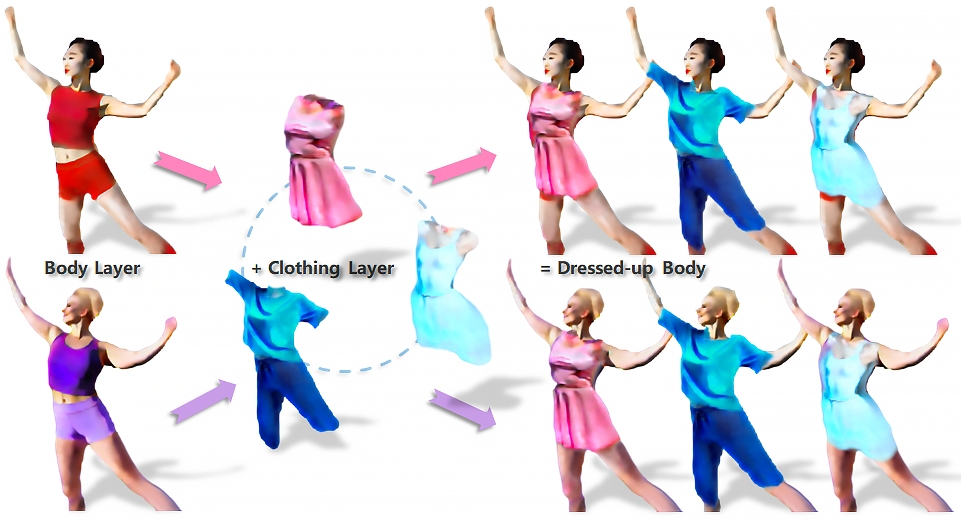 |
| HumanCoser: Layered 3D Human Generation via Semantic-Aware Diffusion Model |
| ISMAR, 2024 Code |
| The generation of 3D clothed humans has attracted increasing attention in recent years. However, existing work cannot generate layered high-quality 3D humans with consistent body structures. As a result, these methods are unable to arbitrarily and separately change and edit the body and clothing of the human. In this work, we propose a text-driven layered 3D human generation framework based on a novel physically-decoupled semantic-aware diffusion model. |
|
 |
| LPSNet: End-to-End Human Pose and Shape Estimation with Lensless Imaging |
| CVPR, 2024 Code |
| Lensless imaging system can have a smaller size, simpler structure and stronger privacy protection attributes, and hence can be adapted to a variety of complex environments. In this paper, we propose the first end-to-end framework to recover 3D human poses and shapes from lensless measurements, to our best knowledge. |
|
 |
| Joint2Human: High-quality 3D Human Generation via Compact Spherical Embedding of 3D Joints |
| CVPR, 2024 Code |
| 3D human generation is increasingly significant in various applications. However, the direct use of 2D generative methods in 3D generation often results in significant loss of local details, while methods that reconstruct geometry from generated images struggle with global view consistency. In this work, we introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details. |
|
 |
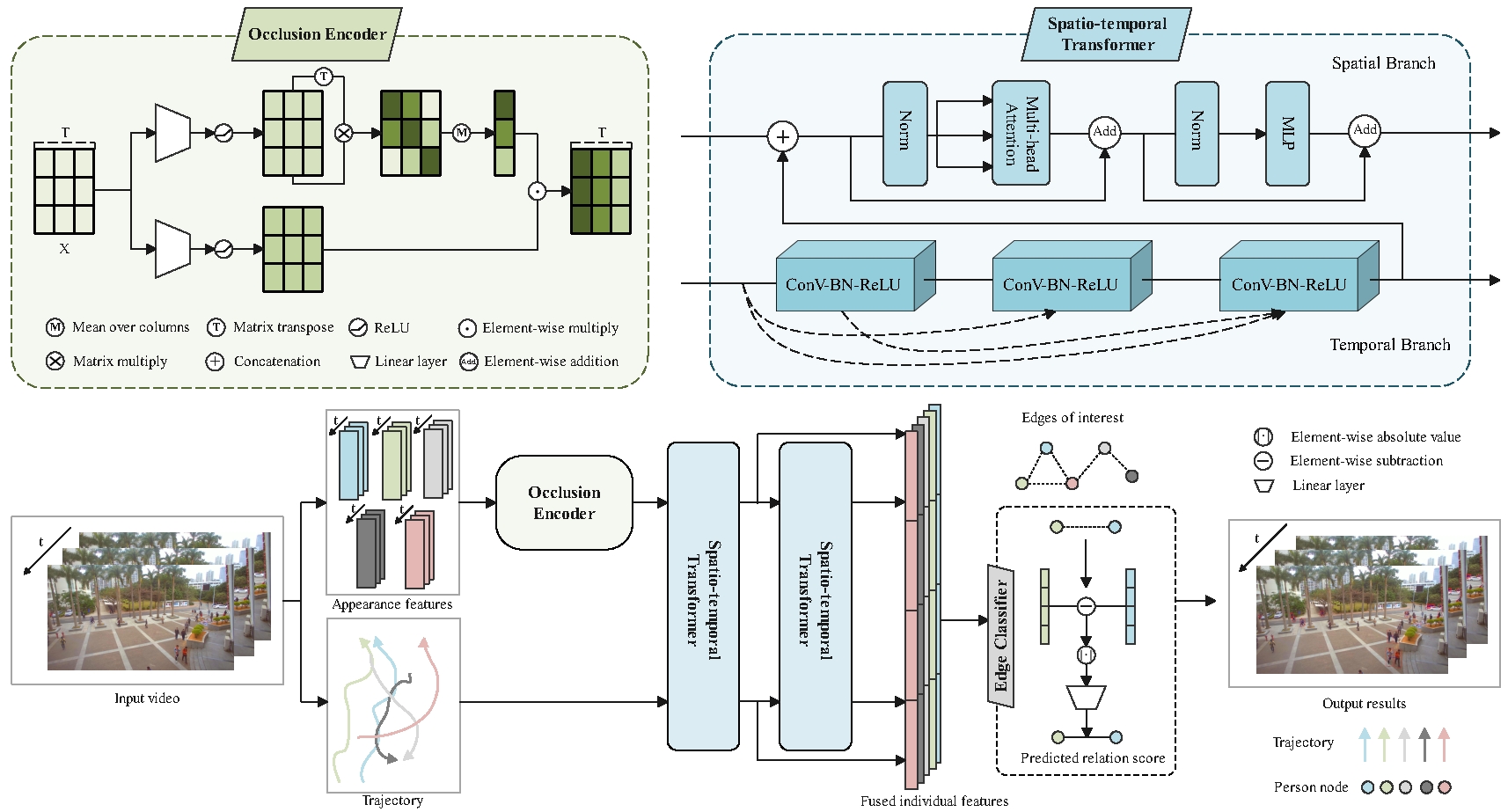
| High-Quality Animatable Dynamic Garment Reconstruction from Monocular Videos |
| IEEE TCSVT, 2024 Code |
| Much progress has been made in reconstructing garments from an image or a video. However, none of existing works meet the expectations of digitizing high-quality animatable dynamic garments that can be adjusted to various unseen poses. In this paper, we propose the first method to recover high-quality animatable dynamic garments from monocular videos without depending on scanned data. |
|
 |
|
 |
| HDhuman: High-quality Human Novel-view Rendering from Sparse Views |
| IEEE TVCG, 2024 Code |
| We aim to address the challenge of novel view rendering of human performers that wear clothes with complex texture patterns using a sparse set of camera views. Our method can render high-quality images at 2k resolution on novel views, and it is a general framework that is able to generalize to novel subjects. |
|
 |
|
 |
|
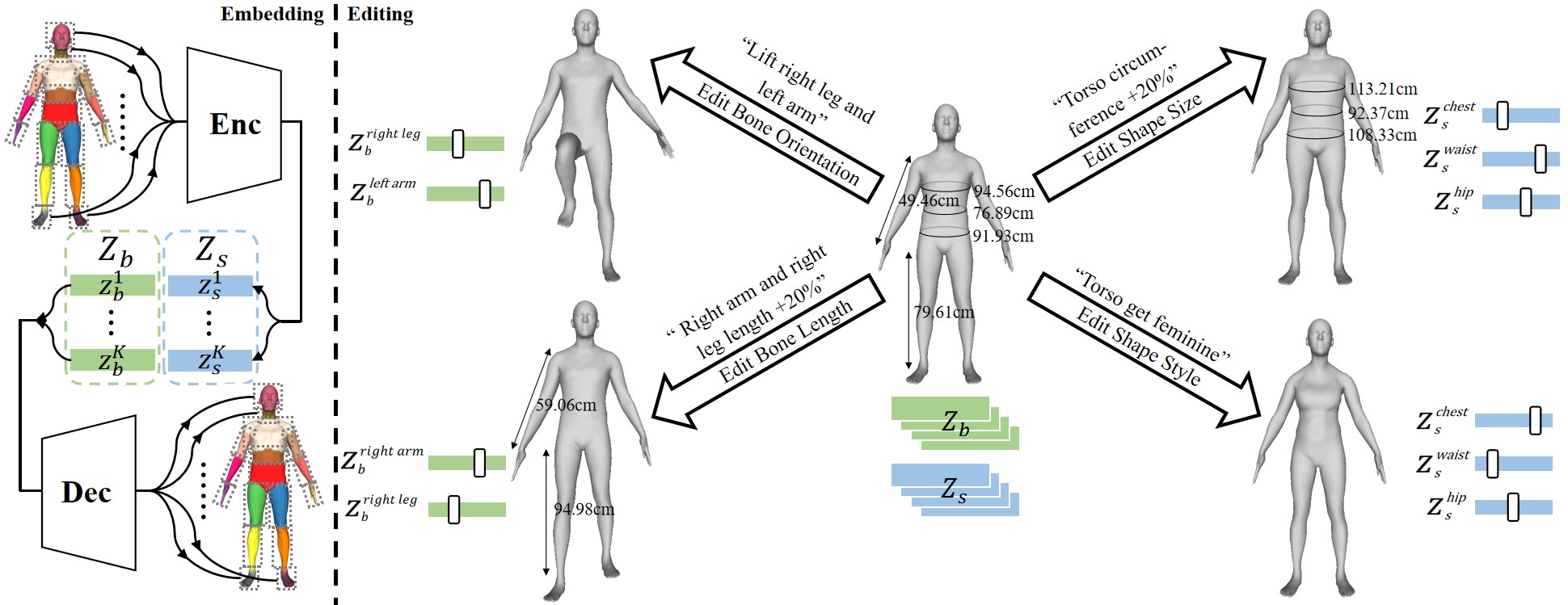 |
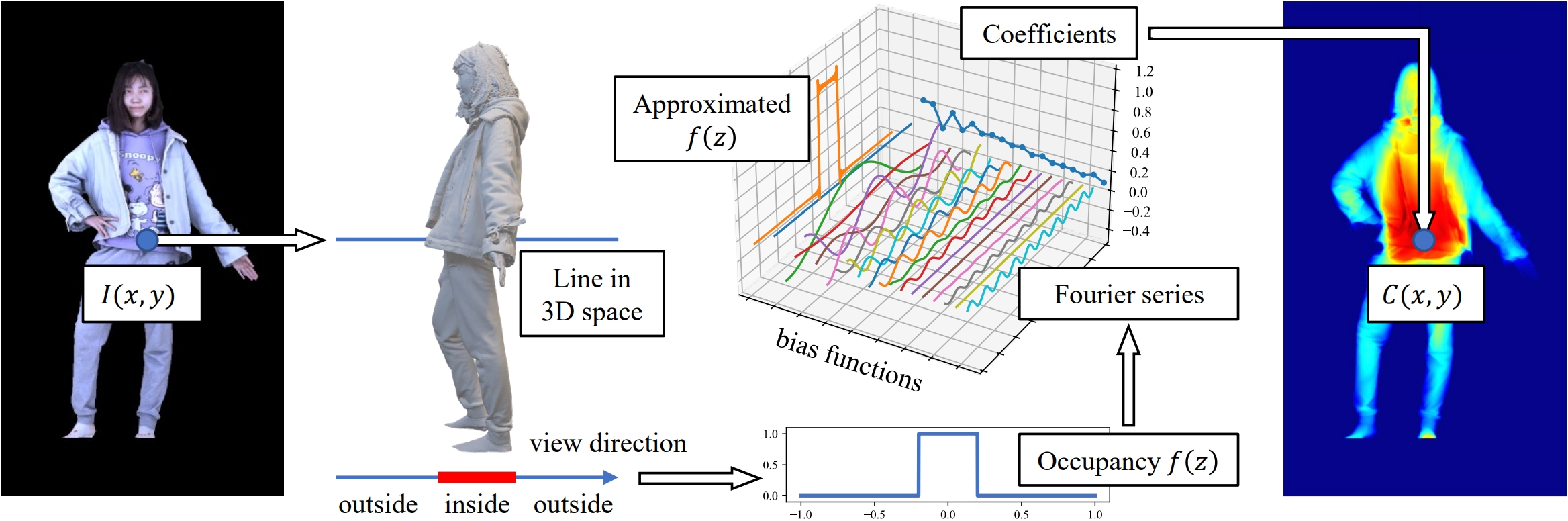
| Learning Semantic-Aware Disentangled Representation for Flexible 3D Human Body Editing |
| CVPR, 2023 Code |
| 3D human body representation learning has received increasing attention in recent years. However, existing works cannot flexibly, controllably and accurately represent human bodies, limited by coarse semantics and unsatisfactory representation capability, particularly in the absence of supervised data. In this paper, we propose a human body representation with fine-grained semantics and high reconstruction-accuracy in an unsupervised setting. |
|
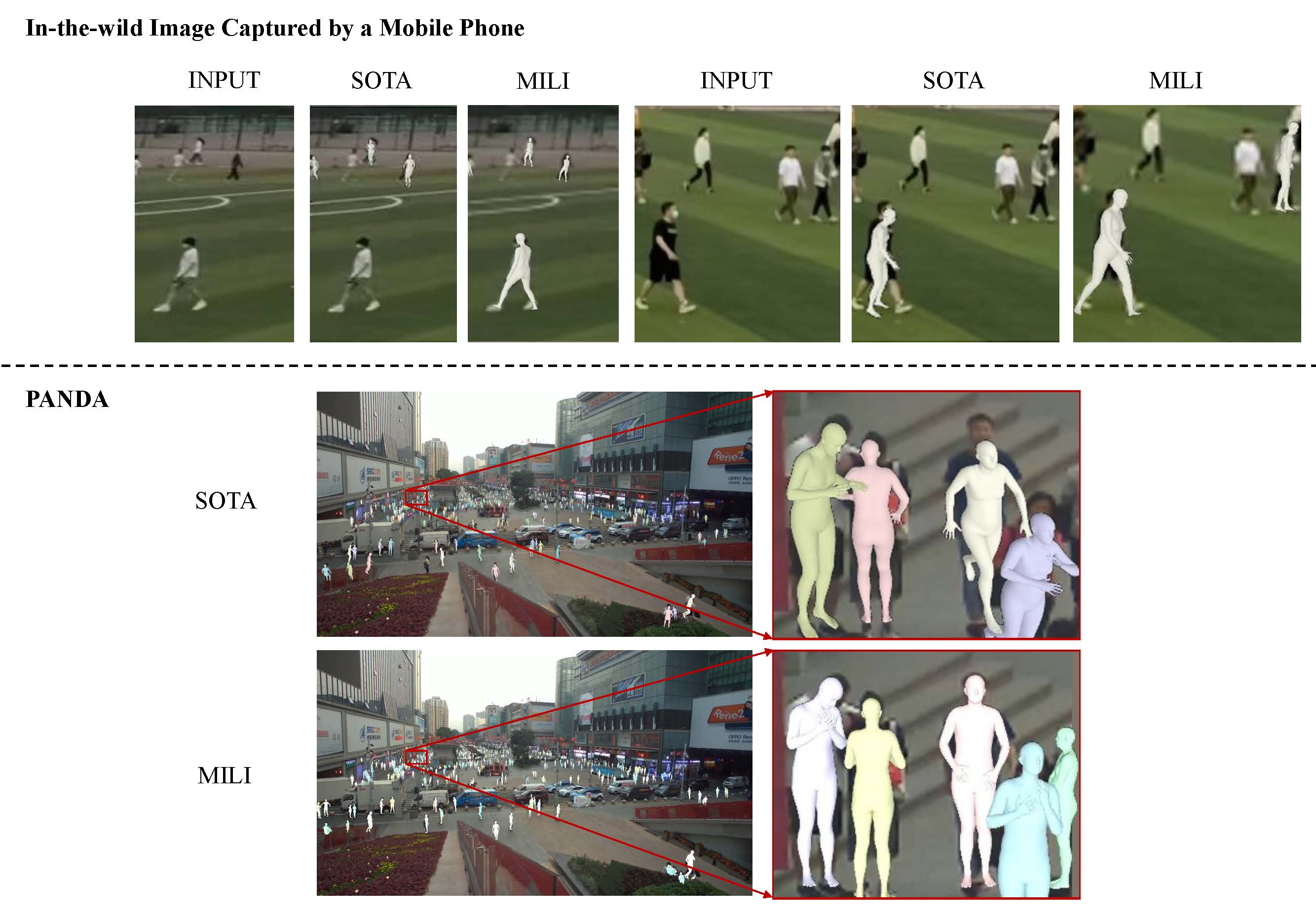 |
| MILI: Multi-person Inference from a Low-resolution Image |
| Fundamental Research 2023 Code |
| Existing multi-person reconstruction methods require the human bodies in the input image to occupy a considerable portion of the picture. However, low-resolution human objects are ubiquitous due to trade-off between the field of view and target distance given a limited camera resolution. In this paper, we propose an end-to-end multi-task framework for multi-person inference from a low-resolution image (MILI). |
|
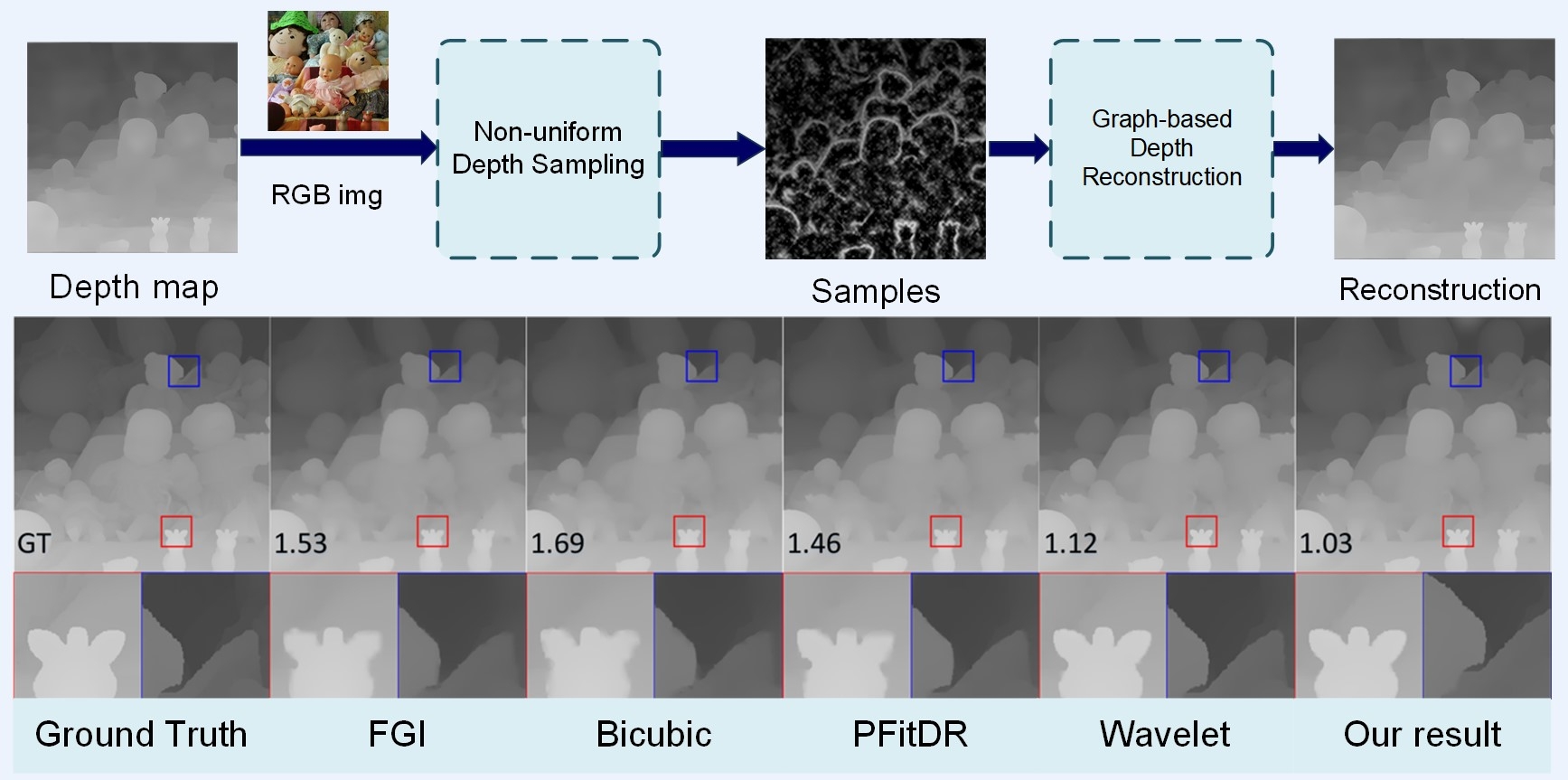 |
| High-Quality Reconstruction of Depth Maps From Graph-Based Non-Uniform Sampling |
| IEEE TMM, 2023 |
| Lensless imaging system can have a smaller size, simpler structure and stronger privacy protection attributes, and hence can be adapted to a variety of complex environments. In this paper, we propose the first end-to-end framework to recover 3D human poses and shapes from lensless measurements, to our best knowledge. |
|
 |
|
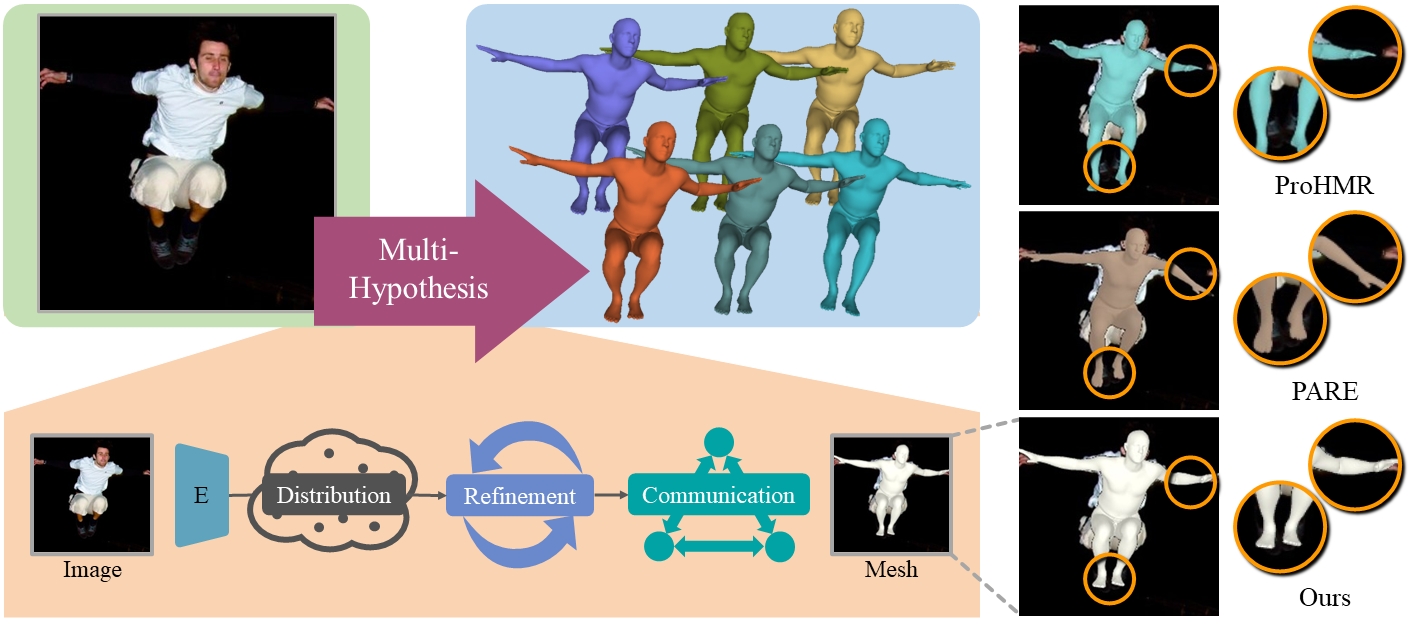 |
| MH-HMR: Human Mesh Recovery from Monocular Images via Multi-Hypothesis Learning |
| CAAI TRIT 2023 Code |
| Recovering 3D human meshes from monocular images is an inherently ambiguous and challenging task due to depth ambiguity, joint
occlusion and truncation. We propose a novel multi-hypothesis approach, MHHMR, for human mesh recovery, which can efficiently and adequately learn the feature representation of multiple hypotheses. |
|
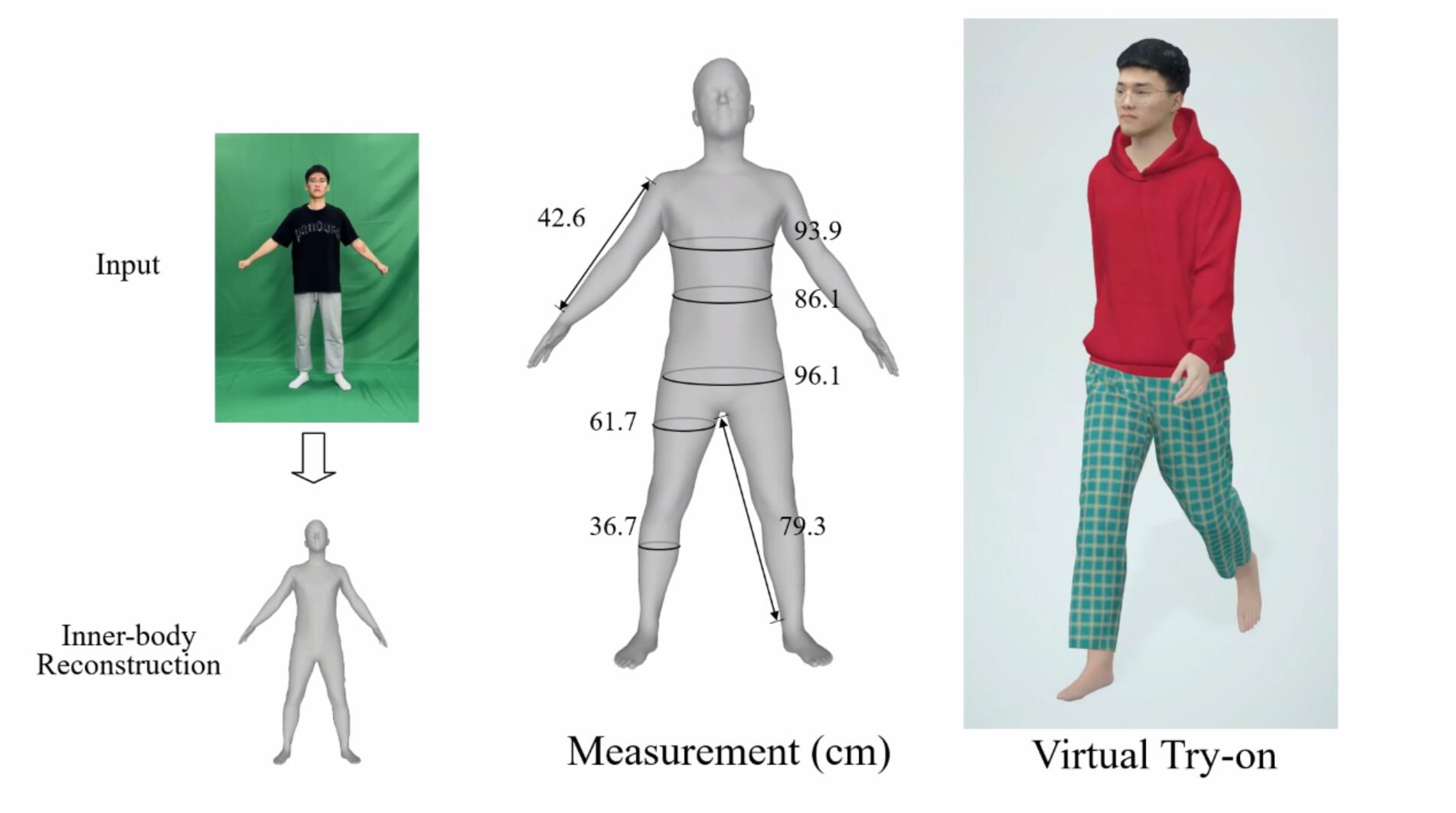 |
| Learning to Infer Inner-Body under Clothing from Monocular Video |
| IEEE TVCG, 2022 Code Dataset |
| Accurately estimating the human inner-body under clothing is very important for body measurement, virtual try-on and VR/AR applications. In this paper, we propose the first method to allow everyone to easily reconstruct their own 3D inner-body under daily clothing from a self-captured video with the mean reconstruction error of 0.73cm within 15s. This avoids privacy concerns arising from nudity or minimal clothing. |
|
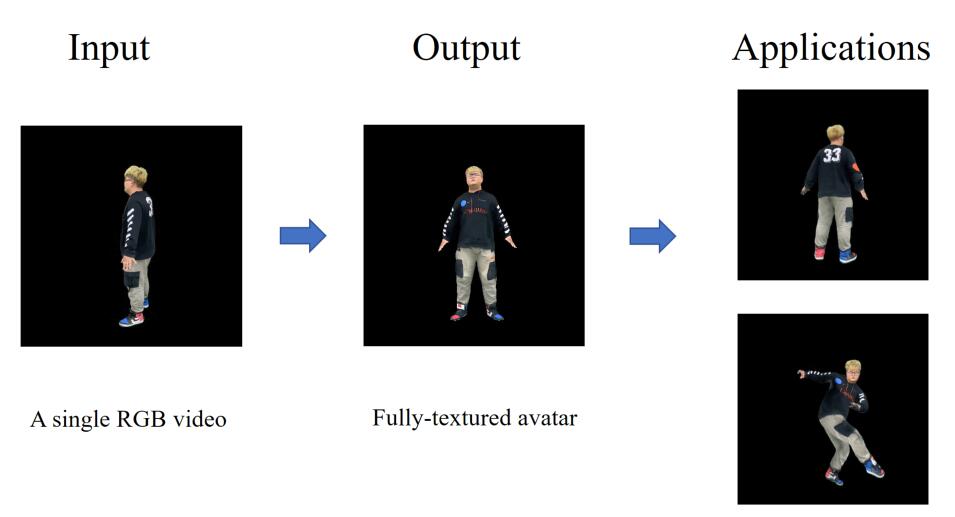 |
| High-Fidelity Human Avatars from a Single RGB Camera |
| CVPR, 2022 Code |
| We propose a coarse-to-fine framework to reconstruct a personalized high-fidelity human avatar from a monocular video. Our framework also enables photo-realistic novel view/pose synthesis and shape editing applications. |
|
 |
|
 |
|
 |
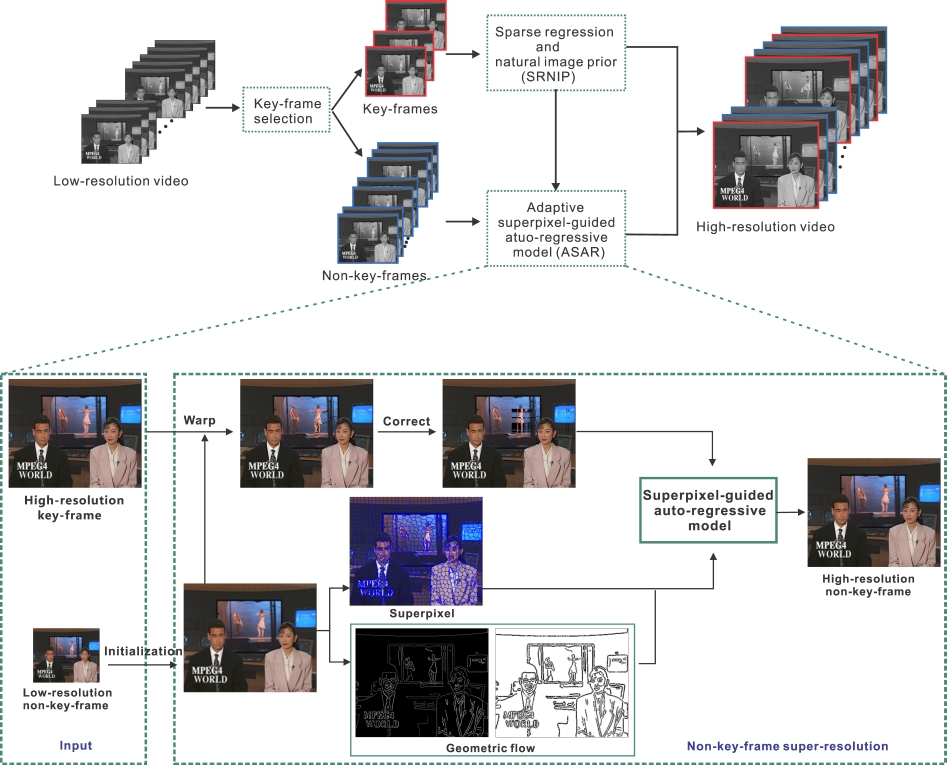
| Implicit Transformer Network for Screen Content Image Continuous Super-Resolution |
| NIPS, 2021 Code |
| We propose a novel Implicit Transformer Super-Resolution Network (ITSRN) for screen content image super-resolution at arbitrary scales. We also construct a benchmark dataset with various screen contents. |
|
 |
|
 |
|
 |
|
 |
|
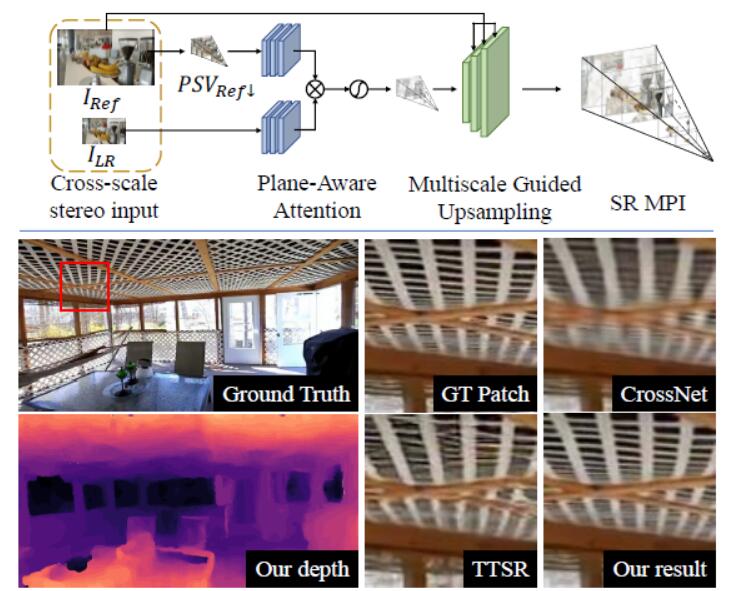 |
| Cross-MPI: Cross-scale Stereo for Image Super-Resolution using Multiplane Images |
| CVPR, 2021 Code |
| This paper proposes an end-to-end reference-based super-resolution network composed of a novel planeaware attention-based MPI mechanism, a multiscale guided upsampling module as well as a super-resolution synthesisand fusion module. |
|
 |
|
 |
|
 |
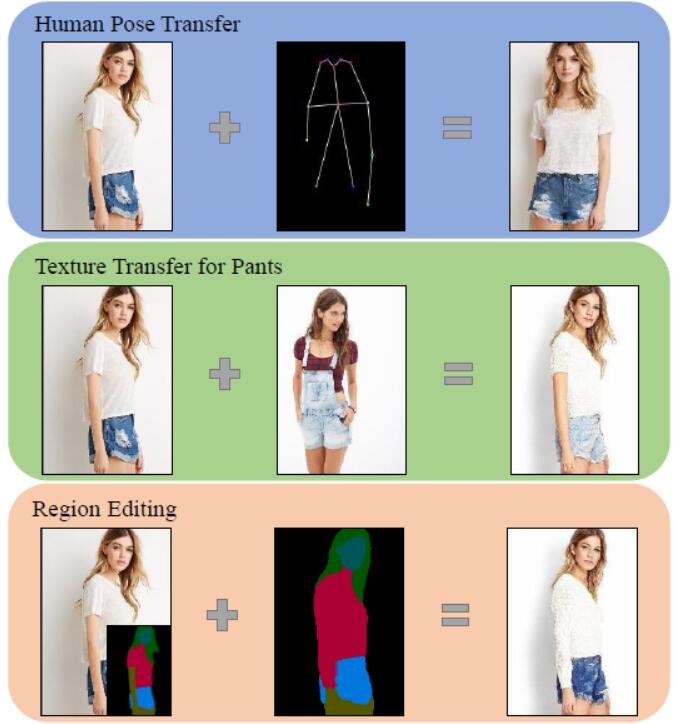
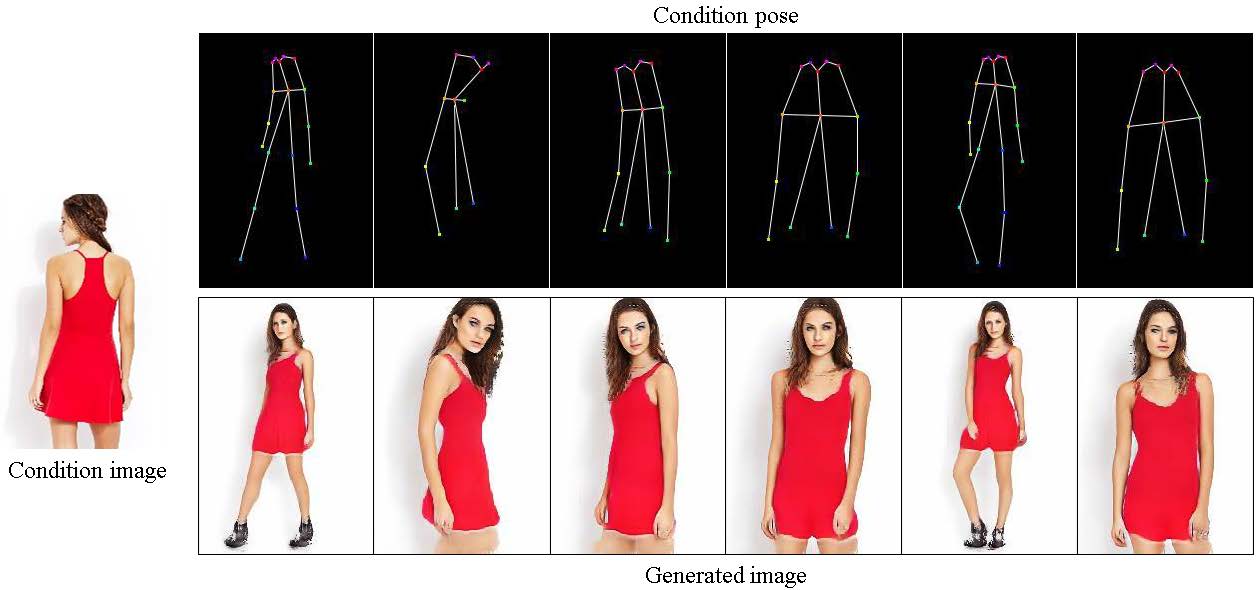
| Human Pose Transfer by Adaptive Hierarchical Deformation |
| Computer Graphics Forum, 2020 (PG2020) Code |
| This paper proposes an adaptive human pose transfer network with two hierarchical deformation levels. Our model has very few parameters and is fast to converge. Furthermore, our method can be applied to clothing texture transfer. |
|
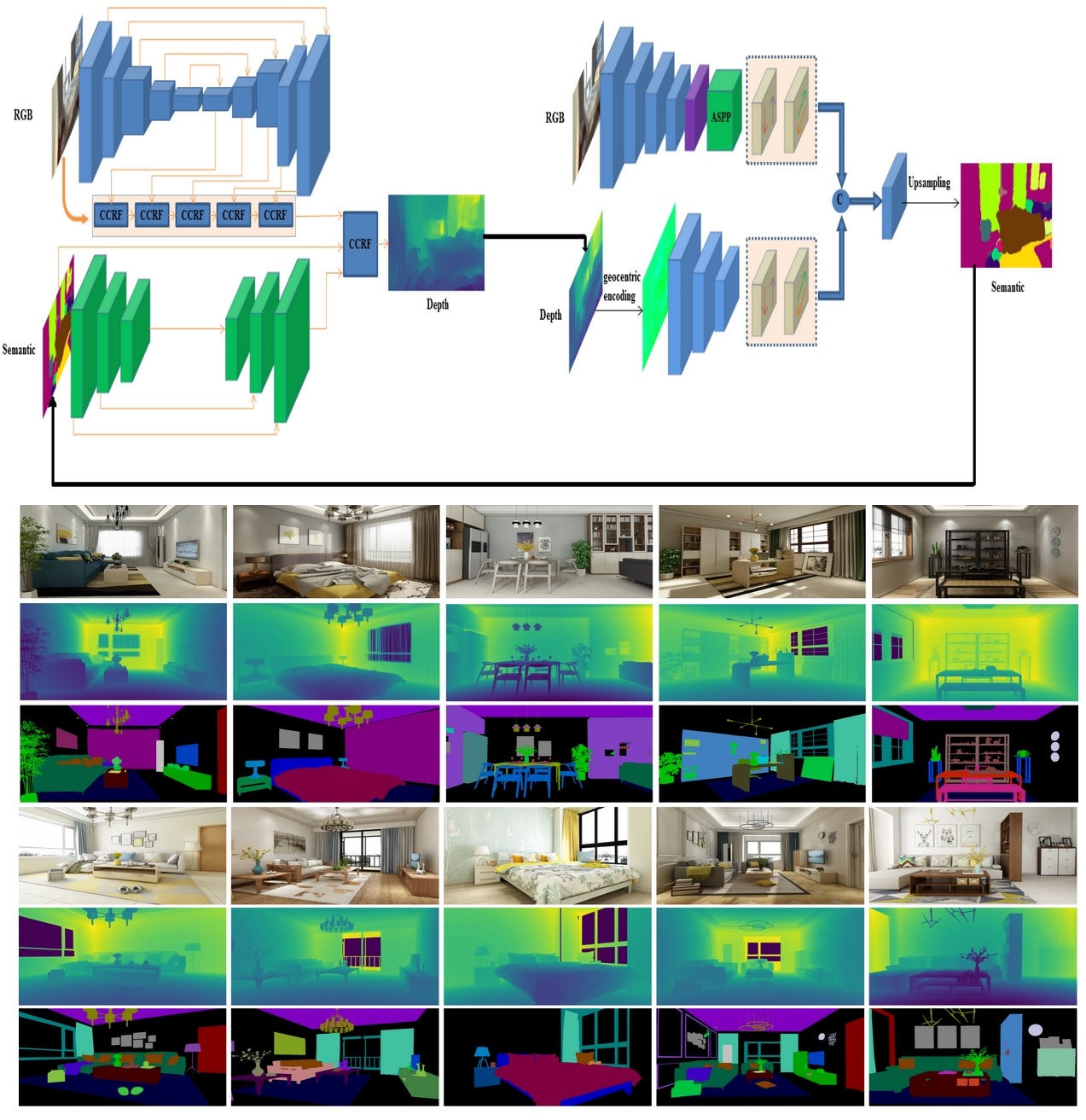 |
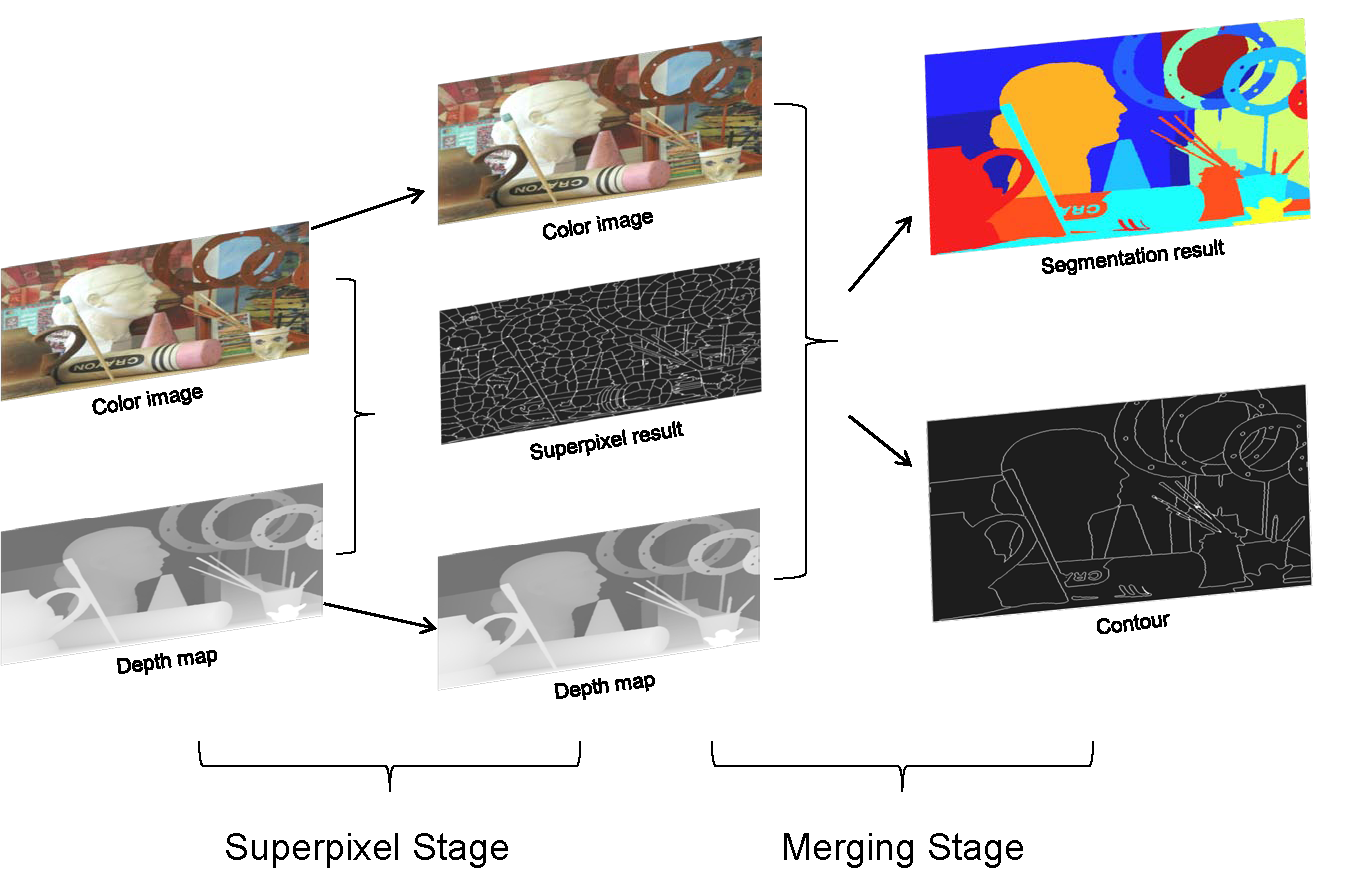
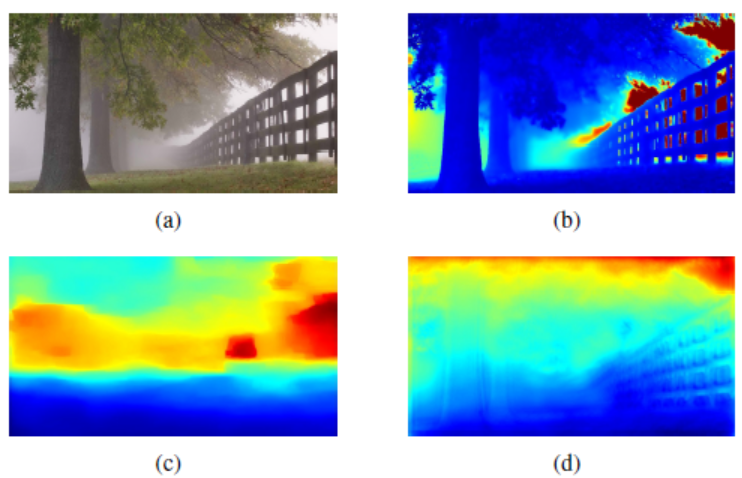
| Learning to Reconstruct and Understand Indoor Scenes from Sparse Views |
| IEEE TIP, 2020 Code Dataset |
| This paper proposes a new method for simultaneous 3D reconstruction and semantic segmentation for indoor scenes. Our method only need a small number of (eg, 3-5) color images from uncalibrated sparse views, which significantly simplifies data acquisition and broadens applicable scenarios. We also make available a new indoor synthetic dataset, containing photorealistic high-resolution RGB images, accurate depth maps and pixel-level semantic labels for thousands of complex layouts. |
|
 |
|
 |
| Full-Body Motion Capture for Multiple Closely Interacting Persons |
| Graphical Models, 2020 |
| In this paper, we present a fully automatic and fast method to capture the total human performance including body poses, facial expression, hand gestures, and feet orientations for closely interacting multiple persons. |
|
 |
|
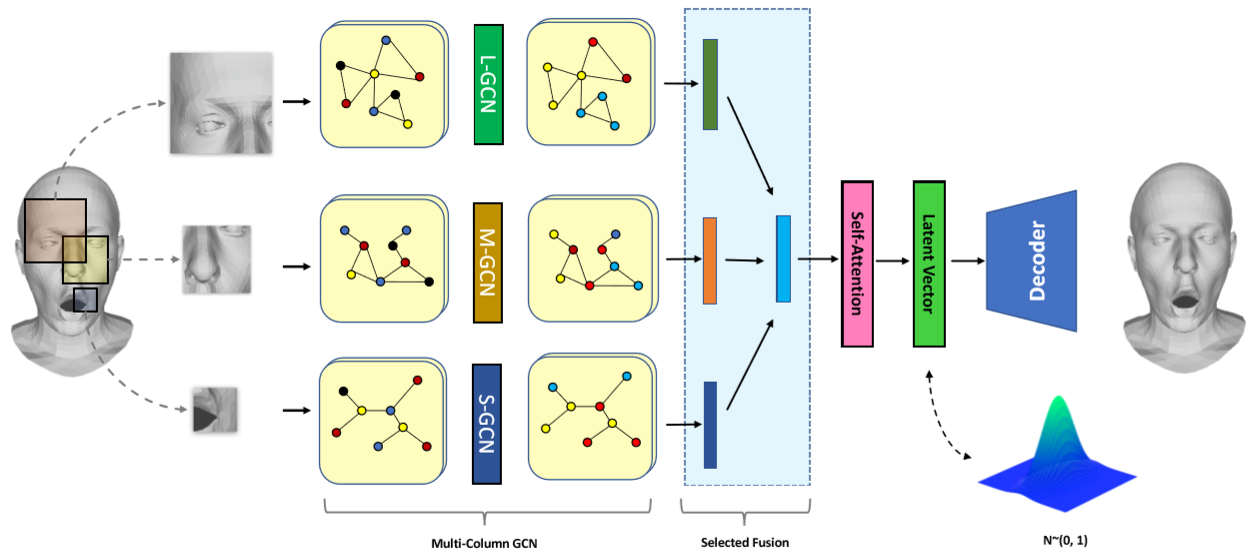 |
| Generating 3D Faces using Multi-column Graph Convolutional Networks |
| Computer Graphics Forum, 2019 (PG2019) Code |
| In this work, we introduce multi-column graph convolutional networks (MGCNs), a deep generative model for 3D mesh surfaces that effectively learns a non-linear facial representation. Moreover, with the help of variational inference, our model has excellent generating ability |
|
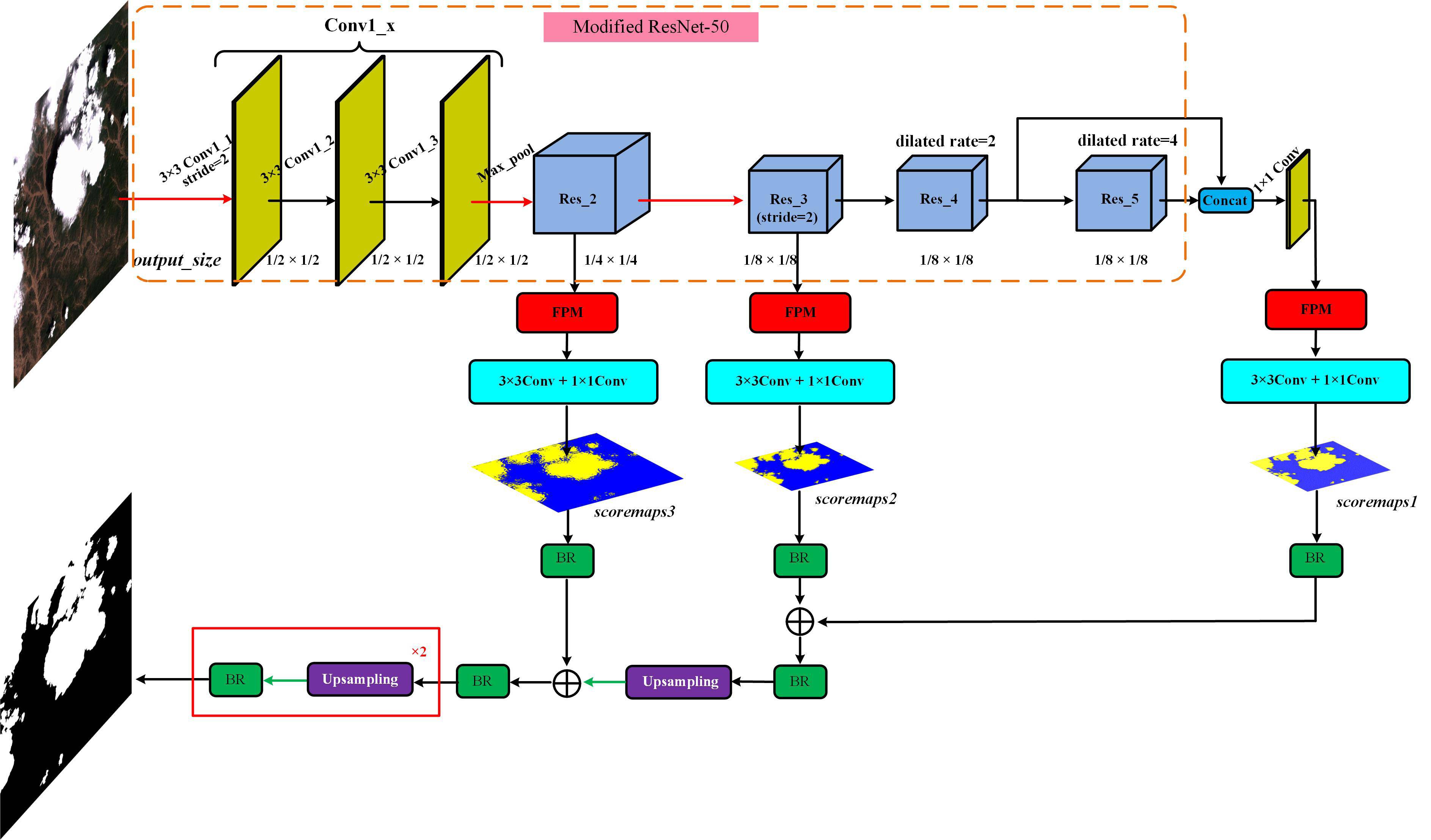 |
| CDnet: CNN-Based Cloud Detection for Remote Sensing Imagery |
| IEEE Transactions on Geoscience and Remote Sensing, 2019 |
| Cloud detection is one of the important tasks for remote sensing image (RSI) preprocessing. In this paper, we utilize the thumbnail (i.e., preview image) of RSI, which contains the information of original multispectral or panchromatic imagery, to extract cloud mask efficiently. We also propose a cloud detection neural network (CDnet) with an encoder-decoder structure, a feature pyramid module (FPM), and a boundary refinement (BR) block. |
|
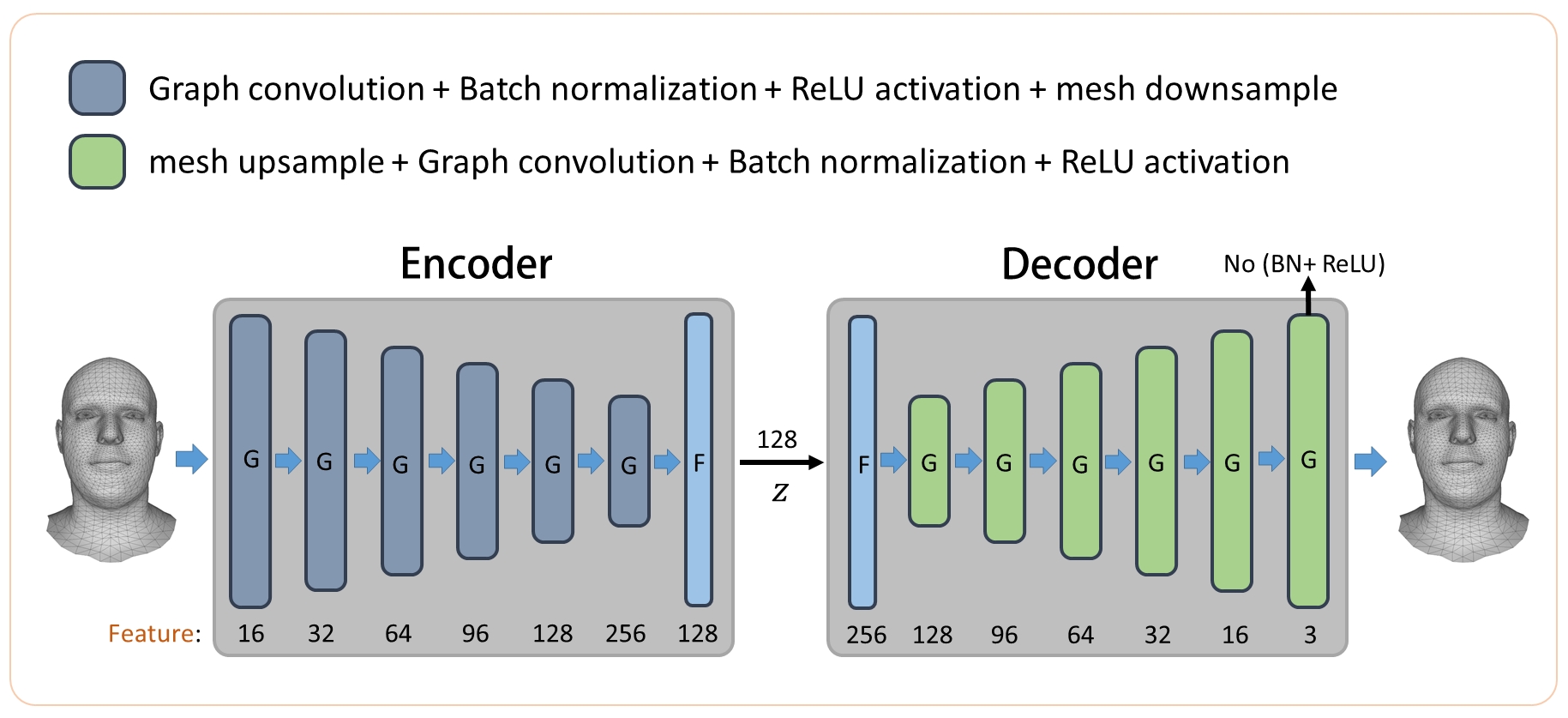 |
| 3D Face Reprentation and Reconstruction with Multi-scale Graph Convolutional Autoencoders |
| IEEE ICME, 2019 |
| We propose a multi-scale graph convolutional autoencoder for face representation and reconstruction. Our autoencoder uses graph convolution, which is easily trained for the data with graph structures and can be used for other deformable models. Our model can also be used for variational training to generate high quality face shapes. |
|
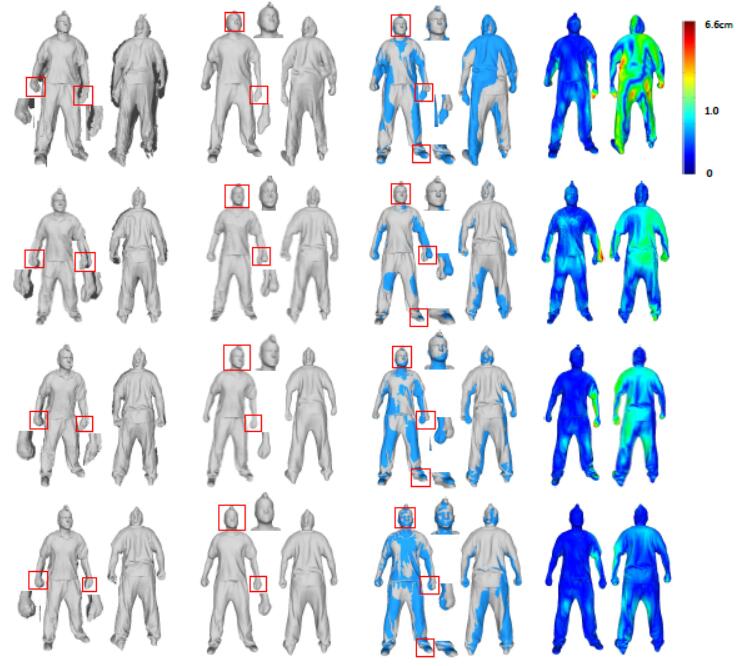 |
| Global As-Conformal-As-Possible Non-Rigid Registration of Multi-View Scans |
| IEEE ICME, 2019 |
| We present a novel framework for global non-rigid registration of multi-view scans captured using consumer-level depth cameras. All scans from different viewpoints are allowed to undergo large non-rigid deformations and finally fused into a complete high quality model. |
|
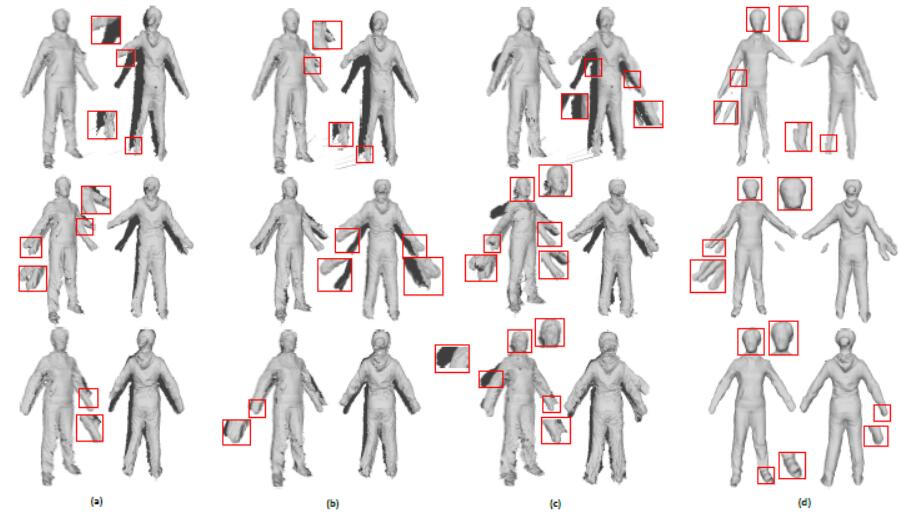 |
| Global 3D Non-Rigid Registration of Deformable Objects Using a Single RGB-D Camera |
| IEEE TIP, 2019 |
| We present a novel global non-rigid registration method for dynamic 3D objects. Our method allows objects to undergo large non-rigid deformations, and achieves high quality results even with substantial pose change or camera motion between views. In addition, our method does not require a template prior and uses less raw data than tracking based methods since only a sparse set of scans is needed. |
|
|
| Robust Non-Rigid Registration with Reweighted Position and Transformation Sparsity |
| IEEE TVCG, 2019 Won in the SHREC 2019 Contest |
| We propose a robust non-rigid registration method using reweighted sparsities on position and transformation to estimate the deformations between 3-D shapes. |
|
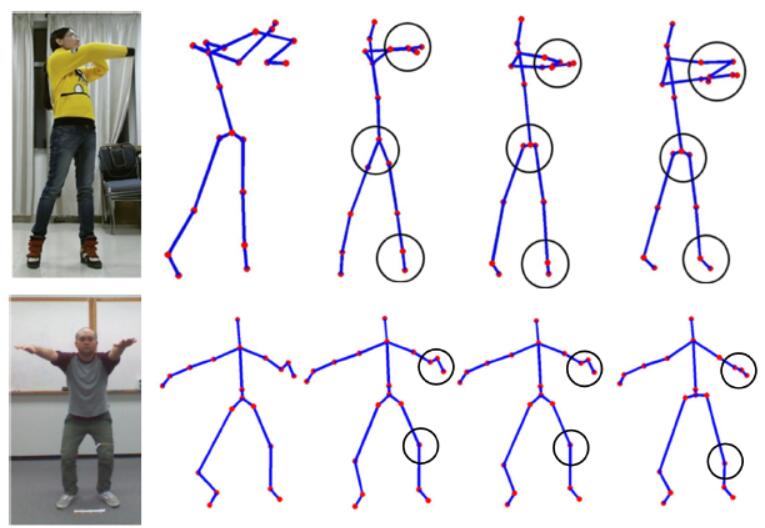 |
| Spatio-Temporal Reconstruction for 3D Motion Recovery |
| IEEE TCSVT, 2019 |
| We address the challenge of 3D motion recovery by exploiting the spatio--temporal correlations of corrupted 3D skeleton sequences. |
|
 |
| Tensor Completion From Structurally-Missing Entries by Low-TT-rankness and Fiber-wise Sparsity |
| JSTSP 2018 |
| Most tensor completion methods assume that missing entries are randomly distributed in incomplete tensors, but this could be violated in practical applications where missing entries are not only randomly but also structurally distributed.
To remedy this, we propose a novel tensor completion method equipped with double priors on the latent tensor, named tensor completion from structurally-missing entries by low tensor train (TT) rankness and fiber-wise sparsity. |
|
|
|