TVCG 2022
Learning to Infer Inner-Body under Clothing from Monocular Video
Xiongzheng Li1, Jing Huang1, Jinsong Zhang1, Xiaokun Sun1, Haibiao Xuan1, Yu-Kun Lai2, Yingdi Xie3, Jingyu Yang1, Kun Li1*
1 Tianjin University 2 Cardiff University 3 VRC Inc.
* Corresponding author
[Code] [Dataset] [Paper]
Abstract
In this paper, we propose the first method to allow everyone to easily reconstruct their own 3D inner-body under daily clothing from a self-captured video with the mean reconstruction error of 0.73cm within 15s. This avoids privacy concerns arising from nudity or minimal clothing. Specifically, we propose a novel two-stage framework with a Semantic-guided Undressing Network (SUNet) and an Intra-Inter Transformer Network (IITNet). SUNet learns semantically related body features to alleviate the complexity and uncertainty of directly estimating 3D inner-bodies under clothing. IITNet reconstructs the 3D inner-body model by making full use of intra-frame and inter-frame information, which addresses the misalignment of inconsistent poses in different frames. Experimental results on both public datasets and our collected dataset demonstrate the effectiveness of the proposed method. The code and the dataset will be provided for research purposes.
Method
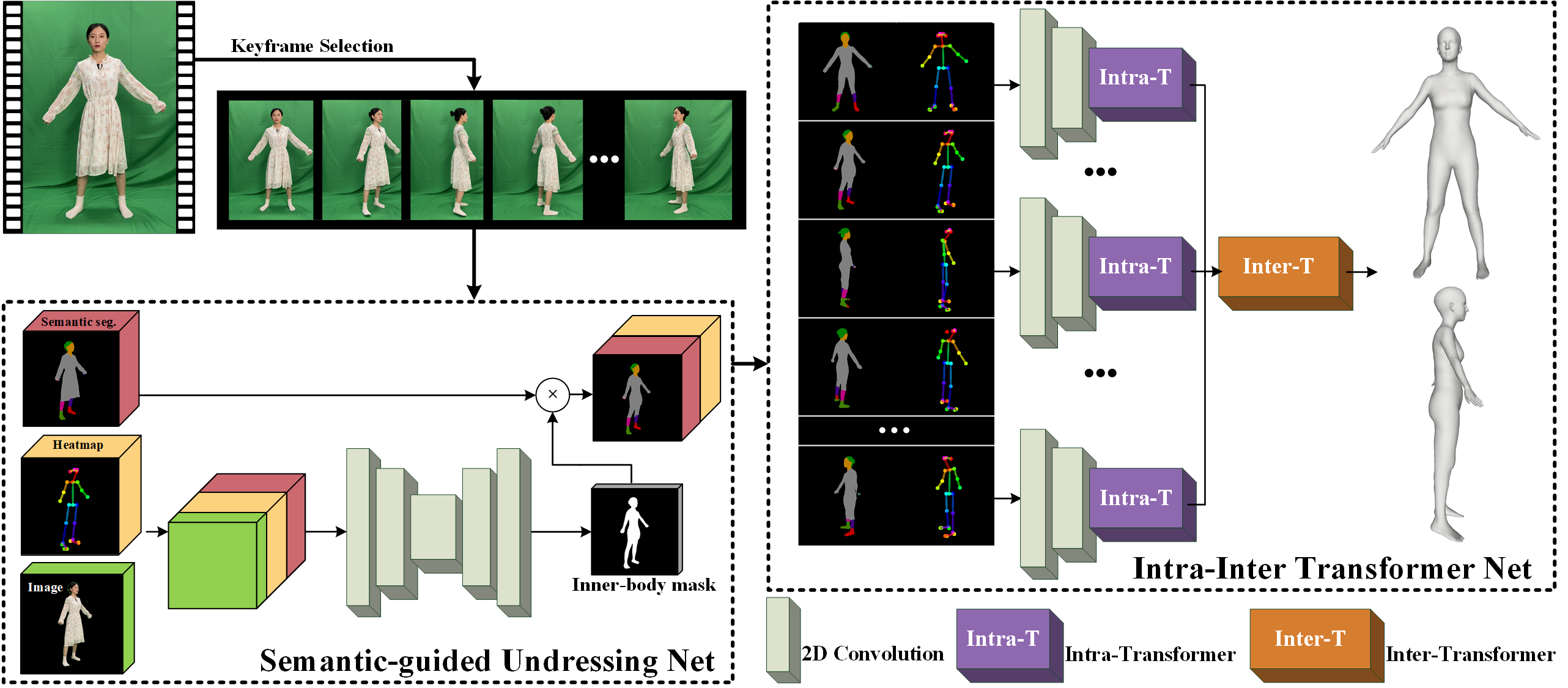
Fig 1. Method overview.
Demo
Results
Application
Technical Paper
Citation
Xiongzheng Li, Jing Huang, Jinsong Zhang, Xiaokun Sun, Haibiao Xuan, Yu-Kun Lai, Yingdi Xie, Jingyu Yang, Kun Li. "Learning to Infer Inner-Body under Clothing from Monocular Video". IEEE Transactions on Visualization and Computer Graphics 2022.
@article{li2022tvcg,
author = {Xiongzheng Li and Jing Huang and Jinsong Zhang and Xiaokun Sun and Haibiao Xuan and Yu-Kun Lai and Yingdi Xie and Jingyu Yang and Kun Li},
title = {Learning to Infer Inner-Body under Clothing from Monocular Video},
booktitle = {IEEE Transactions on Visualization and Computer Graphics},
year={2022},
}