Computational Visual Media 2022
STATE: Learning Structure and Texture Representations
for Novel View Synthesis
Xinyi Jing1†, Qiao Feng1†, Yu-Kun Lai2, Jinsong Zhang1, Yuanqiang Yu1, Kun Li1*
1 Tianjin University 2 Cardiff University
† Equal contribution * Corresponding author
[Code] [Paper] [Supp.]
Abstract
Novel view synthesis, especially from sparse view images, is very challenging due to large view shifting and occlusions. Existing image-based methods fail to generate reasonable results for invisible regions, while geometry-based methods have difficulties synthesizing detailed textures. In this paper, we propose STATE, an end-to-end deep neural network, for sparse view synthesis by learning STructure And TExture representations. The structure is encoded as a hybrid feature field to predict reasonable structures for invisible regions and maintain original structures for visible regions, and the texture is encoded as a deformed feature map to preserve detailed textures. We propose a hierarchical fusion scheme with intra-branch and inter-branch aggregation, in which spatio-view attention is designed for multi-view fusion at the feature level to adaptively select important information by regressing pixel-wise or voxel-wise confidence maps. Through decoding the aggregated features, STATE is able to generate realistic images with reasonable structures and detailed textures. Experimental results demonstrate that our method achieves better performance than state-of-the-art methods in both qualitative and quantitative evaluations. Our method also enables texture and structure editing applications benefitting from implicit disentanglement of structures and textures.
Method
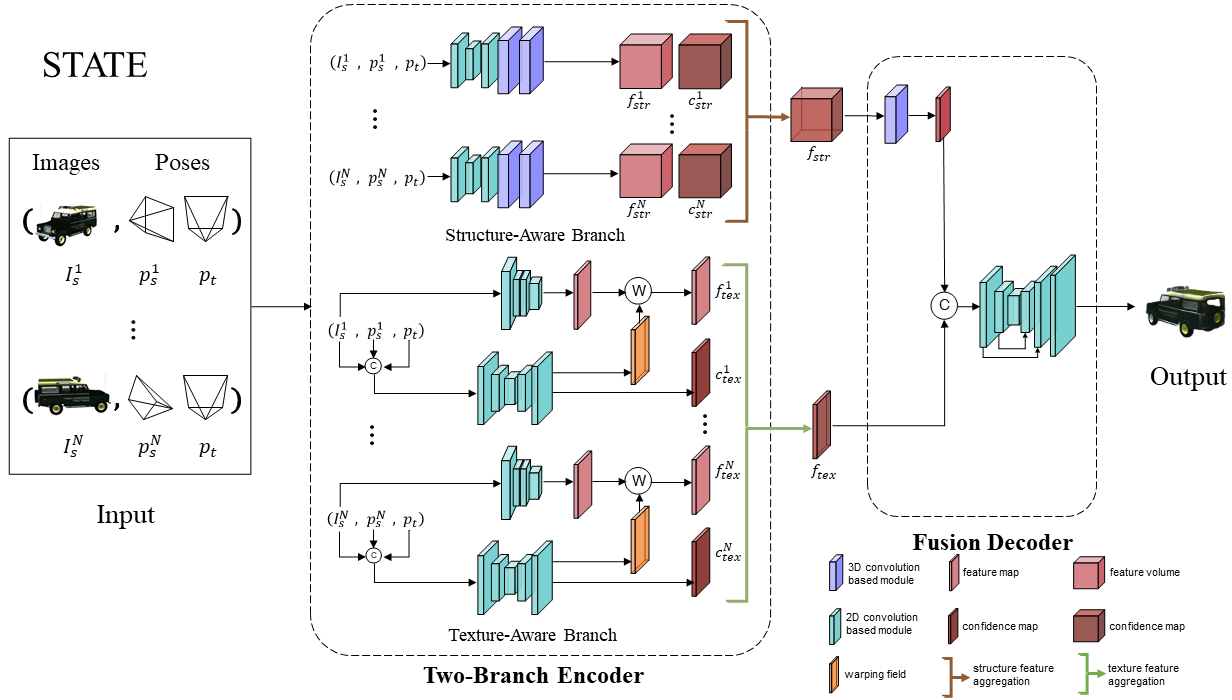
Fig 1. Method overview.
Video
Results

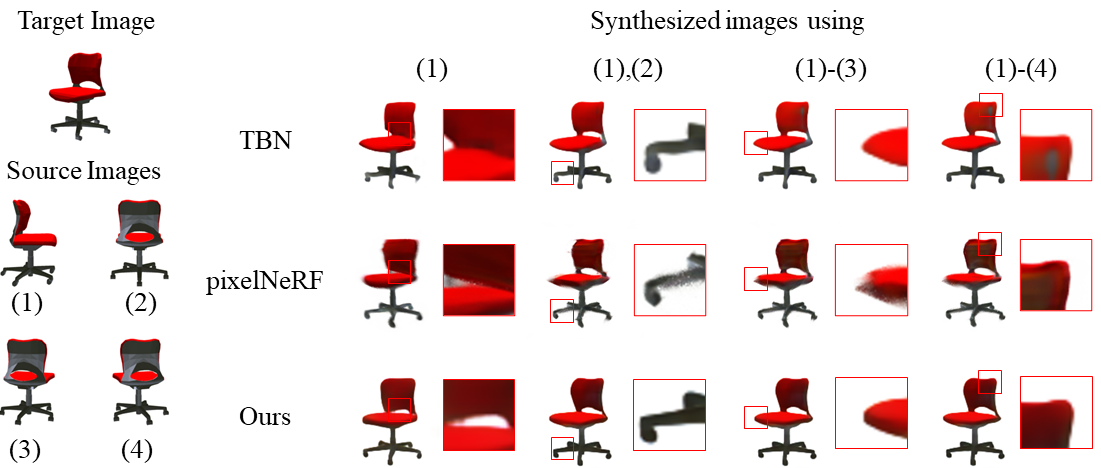
Fig 2. Qualitative comparison on Chair dataset.
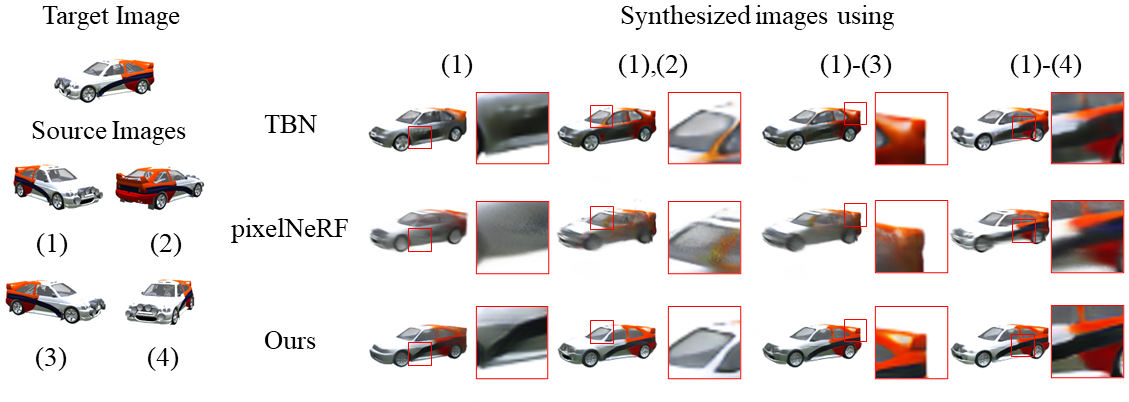
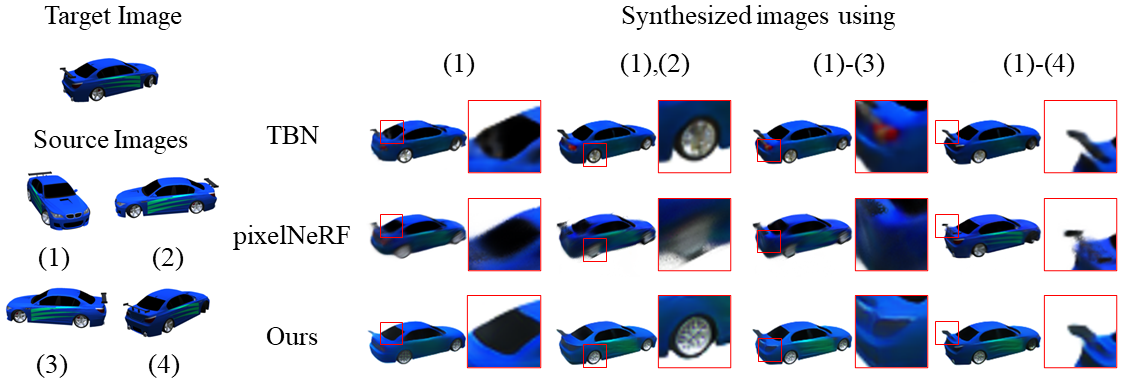
Fig 3. Qualitative comparison on Car dataset.

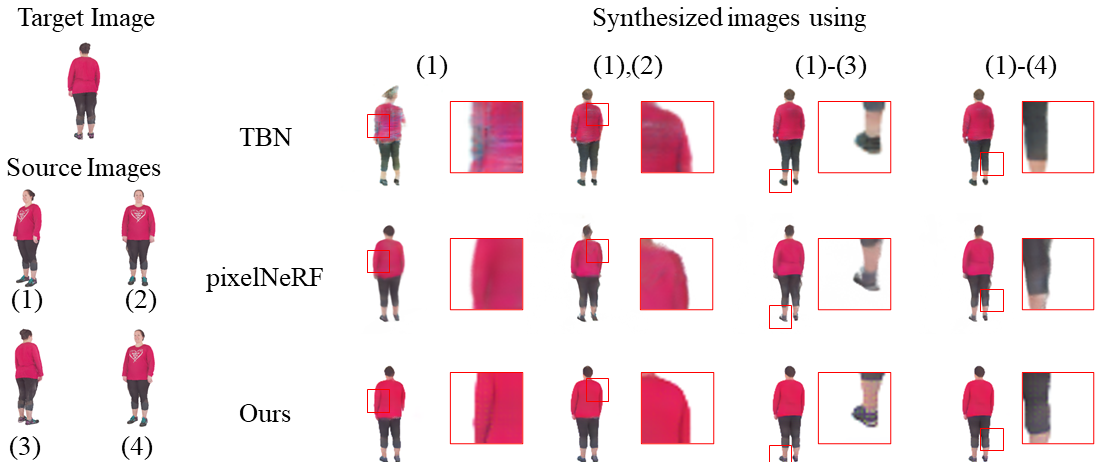
Fig 4. Qualitative comparison on Human dataset.

Fig 5. The results of texture or structure swapping.
Technical Paper

Citation
Xinyi Jing, Qiao Feng, Yu-kun Lai, Jinsong Zhang, Yuanqiang Yu, Kun Li. "STATE: Learning structure and texture representations for novel view synthesis". Computational Visual Media 2022.
@inproceedings{STATE,
author = {Xinyi Jing and Qiao Feng and Yu-kun Lai and Jinsong Zhang and Yuanqiang Yu and Kun
Li},
title = {STATE: Learning structure and texture representations for novel view synthesis},
booktitle = {Computational Visual Media},
year={2022},
}