Foreground-Background Separation From Video Clips
via Motion-Assisted Matrix Restoration
Xinchen Ye, Jingyu Yang, Xin Sun, Kun Li, Chunping Hou, and Yao Wang
Abstract
Separation of video streams into foreground and background components is a useful and important technique in video analysis, making recognition, classification and scene analysis more efficient. In this paper, we propose a motion-assisted matrix restoration (MAMR) model for foreground-background separation from video clips. The backgrounds across frames are modeled by a low-rank matrix, while the foreground objects are modeled by a sparse matrix. To facilitate efficient foreground-background separation, a dense motion field is estimated for each frame, and mapped into a weighting matrix which indicates the likelihood that each pixel belongs to the background. Anchor frames are selected in the dense motion estimation to overcome the difficulty of detecting slowly-moving objects and camouflages. Then the foreground is computed by the background subtraction technique using the recovered background image. In addition, we extend our model to a robust MAMR model (RMAMR) which is robust to noise for practical applications. In the experiment, we compare our MAMR and RMAMR models with other state-of-the-art methods on challenging datasets. Experimental results demonstrate that our method is quite versatile for surveillance videos with different types of motions and lighting conditions, and outperforms many other state-of-the-art methods.
Keywords: Background extraction, optical flow, motion detection, matrix restoration, video surveillance.
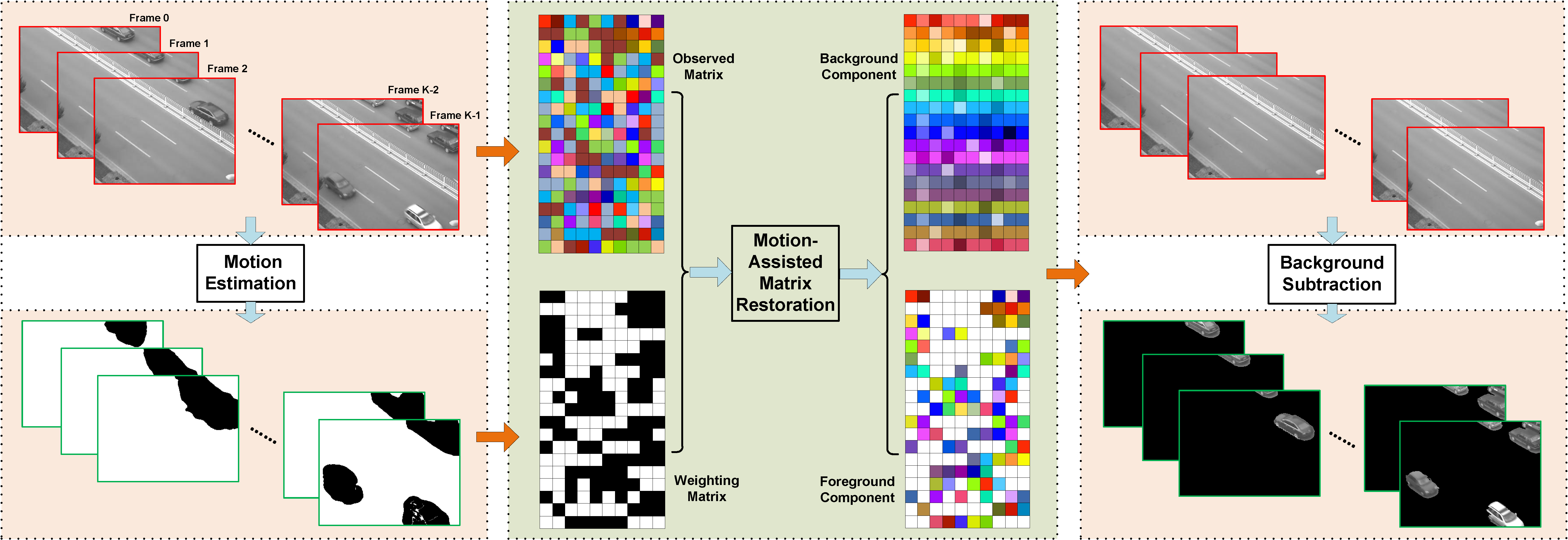
Fig. 1. The work flow of the proposed method.
Downloads
Datasets: Various datasets can be downloaded via the links attached to the following tables and figures.
Source code: Coming soon....
Effect of α in Motion-to-Weight Mapping
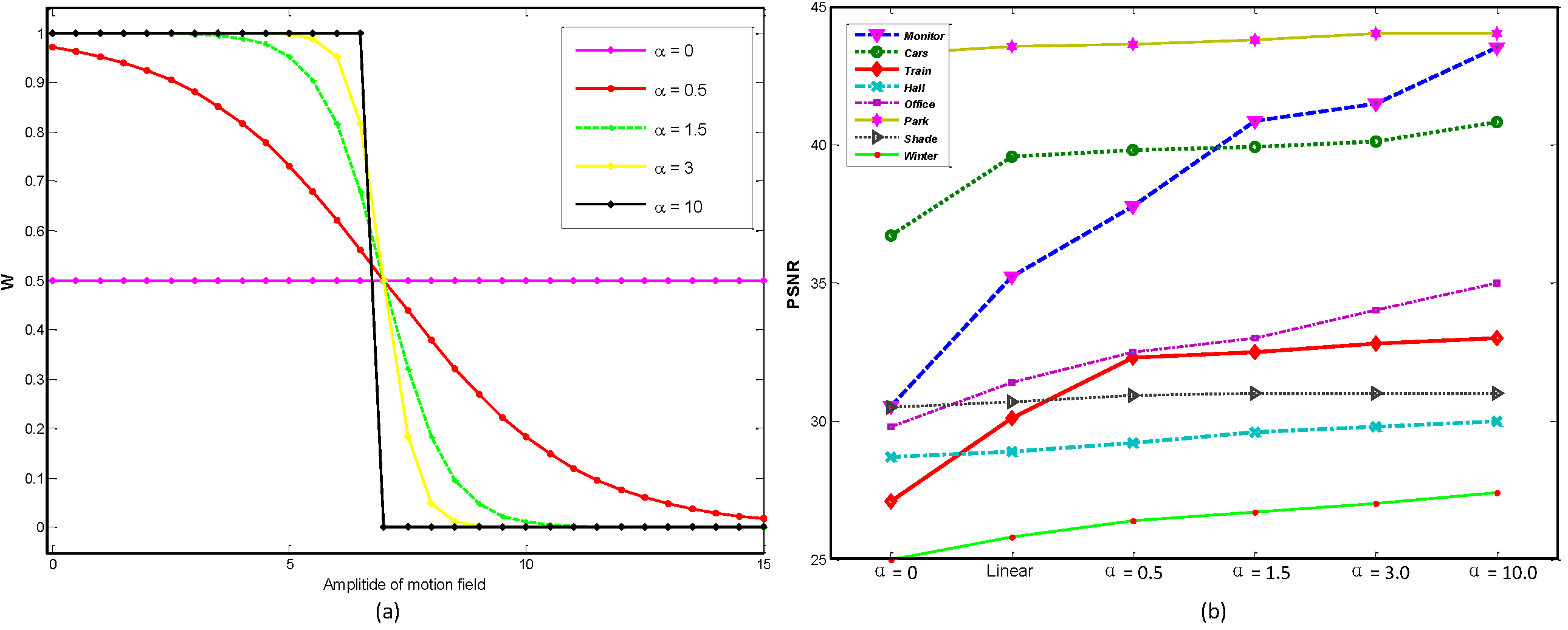
Fig.1. (a) The mapping between weighting matrix W and motion field (Ox , Oy) using steerable sigmoid function. (b) Objective comparison with different values of α for recovered backgrounds on ten video clips. The values are computed against ground-truths in PSNR.

Fig.2. Visual quality comparison for recovered background on Monitor (the top row) and Train (the bottom row). Results by (a) PCP (α = 0) [4], (b) linear, (c) α = 0.5, (d) α = 1.5, and (e) α = 3, (f) α = 10.
Performance of Our Method with Different Combining Options
Table 1 : Quantitative foreground detection results on different combining options. Opt1-Opt10 represent ten combining options, in which OF1-OF4 are four optical flows, and AFS denotes the anchor frames selection.
| Opt1 | Opt2 | Opt3 | Opt4 | Opt5 | Opt6 | Opt7 | Opt8 | Opt9 | Opt10 | ||
| Recall | 0.65 | 0.73 | 0.79 | 0.79 | 0.81 | 0.8 | 0.83 | 0.84 | 0.83 | 0.85 | |
| Pre | 0.72 | 0.74 | 0.73 | 0.73 | 0.75 | 0.75 | 0.79 | 0.78 | 0.87 | 0.86 | |
| F1 | 0.67 | 0.71 | 0.76 | 0.78 | 0.78 | 0.78 | 0.81 | 0.81 | 0.83 | 0.85 | |
| Opt1 | Opt2 | Opt3 | Opt4 | Opt5 |
| OF4 + GMM | OF4 + AFS + GMM | OF1 + RPCA | OF2 + RPCA | OF3 + RPCA |
| Opt6 | Opt7 | Opt8 | Opt9 | Opt10 |
| OF4 + RPCA | OF1 + AFS + RPCA | OF2 + AFS + RPCA | OF3 + AFS + RPCA | OF4 + AFS + RPCA |

Fig.3. Visual quality comparison for Binary foreground maps and its corresponding extracted backgrounds in terms of different combining options on the 656th frame of Office and the 1936th frame of Winter: (a) ground-truth pair, (b) GMM [10], (c) Opt1 (OF4[14] + GMM), (d) Opt2 (OF4[14] + AFS + GMM), (e) Opt6 (OF4[14] + RPCA), (f) Opt10 (OF4[14] + AFS+ RPCA). AFS is the short for anchor frames selection.
Evaluation on Real Datasets
1. Visual Comparison Results of Background Extraction

Fig.4. Visual quality comparison for background extraction on ten video clips. Results by (a) Our MAMR model, (b) SOBS [1], (c) LBG [2], (d) MBS [3], (e) PCP [4], (f) OP [5], (g) SSGoDec [6], and (h) SBL [7]. From top to bottom present extracted backgrounds of Office, Canoe, Winter, Boulevard, Shade, Park, Monitor, Cars, Hall and Train, respectively.
Click here to download our results and ground truth in Fig.4
2.Quantitative and Qualitative Results on Foreground Detection
Table 2 : Quantitative foreground separation results on ten video clips.
| Office | Canoe | Winter | Boulevard | Shade | Park | Monitor | Cars | Hall | Train | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | ||||||||||||||||||||||||||||||||
| Ours | 0.85 | 0.86 | 0.85 | 0.78 | 0.87 | 0.81 | 0.68 | 0.72 | 0.70 | 0.68 | 0.75 | 0.73 | 0.80 | 0.81 | 0.80 | 0.70 | 0.76 | 0.74 | 0.94 | 0.94 | 0.94 | 0.87 | 0.81 | 0.84 | 0.85 | 0.88 | 0.86 | 0.76 | 0.93 | 0.84 | |||||||||||||||||||||||||||||||
| ViBe[8] | 0.70 | 0.80 | 0.69 | 0.80 | 0.67 | 0.73 | 0.57 | 0.18 | 0.23 | 0.75 | 0.42 | 0.50 | 0.74 | 0.78 | 0.76 | 0.42 | 0.61 | 0.56 | 0.61 | 0.97 | 0.75 | 0.58 | 0.85 | 0.69 | 0.49 | 0.72 | 0.58 | 0.69 | 0.64 | 0.67 | |||||||||||||||||||||||||||||||
| SOBS[1] | 0.67 | 0.79 | 0.69 | 0.54 | 0.70 | 0.64 | 0.18 | 0.53 | 0.24 | 0.37 | 0.61 | 0.43 | 0.63 | 0.78 | 0.68 | 0.23 | 0.58 | 0.43 | 0.77 | 0.93 | 0.84 | 0.66 | 0.91 | 0.77 | 0.76 | 0.71 | 0.62 | 0.90 | 0.46 | 0.61 | |||||||||||||||||||||||||||||||
| Σ-σ[9] | 0.52 | 0.66 | 0.53 | 0.36 | 0.75 | 0.45 | 0.45 | 0.39 | 0.38 | 0.47 | 0.40 | 0.42 | 0.60 | 0.72 | 0.71 | 0.59 | 0.60 | 0.64 | 0.88 | 0.75 | 0.81 | 0.79 | 0.66 | 0.72 | 0.78 | 0.39 | 0.52 | 0.63 | 0.63 | 0.63 | |||||||||||||||||||||||||||||||
| GMM[10] | 0.53 | 0.82 | 0.59 | 0.51 | 0.62 | 0.49 | 0.39 | 0.58 | 0.45 | 0.57 | 0.56 | 0.46 | 0.75 | 0.71 | 0.72 | 0.59 | 0.64 | 0.60 | 0.74 | 0.78 | 0.76 | 0.86 | 0.76 | 0.81 | 0.52 | 0.21 | 0.30 | 0.57 | 0.15 | 0.24 | |||||||||||||||||||||||||||||||
| SBST[11] | 0.78 | 0.56 | 0.61 | 0.82 | 0.11 | 0.19 | 0.81 | 0.45 | 0.57 | 0.87 | 0.11 | 0.19 | 0.73 | 0.47 | 0.54 | 0.57 | 0.58 | 0.56 | 0.97 | 0.42 | 0.58 | 0.96 | 0.69 | 0.81 | 0.69 | 0.10 | 0.18 | 0.86 | 0.12 | 0.21 | |||||||||||||||||||||||||||||||
| PBAS[12] | 0.78 | 0.76 | 0.77 | 0.62 | 0.94 | 0.74 | 0.47 | 0.39 | 0.38 | 0.65 | 0.75 | 0.58 | 0.73 | 0.77 | 0.75 | 0.48 | 0.72 | 0.56 | 0.91 | 0.81 | 0.86 | 0.77 | 0.82 | 0.79 | 0.54 | 0.70 | 0.61 | 0.73 | 0.62 | 0.67 | |||||||||||||||||||||||||||||||
| FBM[13] | 0.62 | 0.76 | 0.71 | 0.35 | 0.75 | 0.45 | 0.37 | 0.36 | 0.34 | 0.50 | 0.73 | 0.52 | 0.65 | 0.77 | 0.70 | 0.31 | 0.75 | 0.42 | 0.61 | 0.99 | 0.75 | 0.62 | 0.79 | 0.70 | 0.36 | 0.59 | 0.45 | 0.60 | 0.63 | 0.61 | |||||||||||||||||||||||||||||||
| PCP[4] | 0.57 | 0.76 | 0.62 | 0.36 | 0.32 | 0.33 | 0.55 | 0.40 | 0.42 | 0.51 | 0.80 | 0.62 | 0.69 | 0.74 | 0.71 | 0.69 | 0.79 | 0.74 | 0.80 | 0.90 | 0.84 | 0.71 | 0.81 | 0.76 | 0.72 | 0.87 | 0.79 | 0.70 | 0.85 | 0.74 | |||||||||||||||||||||||||||||||
| OP[5] | 0.52 | 0.60 | 0.54 | 0.48 | 0.33 | 0.39 | 0.50 | 0.50 | 0.58 | 0.47 | 0.54 | 0.58 | 0.60 | 0.50 | 0.55 | 0.60 | 0.60 | 0.60 | 0.70 | 0.69 | 0.70 | 0.62 | 0.70 | 0.75 | 0.66 | 0.72 | 0.70 | 0.68 | 0.83 | 0.71 | |||||||||||||||||||||||||||||||
| SSGoDec[6] | 0.67 | 0.73 | 0.66 | 0.64 | 0.35 | 0.42 | 0.61 | 0.52 | 0.55 | 0.62 | 0.57 | 0.60 | 0.72 | 0.74 | 0.73 | 0.71 | 0.75 | 0.73 | 0.77 | 0.89 | 0.78 | 0.85 | 0.78 | 0.81 | 0.72 | 0.86 | 0.79 | 0.73 | 0.70 | 0.71 | |||||||||||||||||||||||||||||||
| SBL[7] | 0.58 | 0.74 | 0.61 | 0.34 | 0.44 | 0.35 | 0.68 | 0.56 | 0.62 | 0.73 | 0.80 | 0.73 | 0.71 | 0.74 | 0.72 | 0.72 | 0.77 | 0.74 | 0.90 | 0.79 | 0.73 | 0.90 | 0.70 | 0.76 | 0.76 | 0.81 | 0.78 | 0.68 | 0.85 | 0.74 | |||||||||||||||||||||||||||||||

Fig. 5. Visual quality comparison for foreground detection on ten video clips: (a) input image frame and (h) corresponding groundtruth binary foreground, (b) our MAMR model, c)ViBe [8], (d)SOBS [1], (e)Σ-σ [9], (f)GMM [10], (g)SBST [11], (i) PBAS [12], (j) FBM [13], (k) PCP [4], (l) OP [5], (m) SSGoDec [6], and (n) SBL [7]. From top to bottom present the 656th frame of Office, the 956th frame of Canoe, the 1936th frame of Winter, the 816th frame of Boulevard, the 481th frame of Shade, the 311th frame of Park, and the 101th frame of Car, the 101th frame of Hall, the 56th frame of Monitor, the 46th frame of Train, respectively.
Click here to download our results and ground truth in Fig.5
Evaluation on Noisy Datasets
1.Quantitative and Qualitative Results of Background Extraction
Table 3 : Quantitative background extraction results in terms of PSNR on synthetic noisy video clips.
| Office | Winter | Shade | Park | Monitor | Cars | Hall | Train | |
| Ours | 34.61 | 27.12 | 31.20 | 46.23 | 39.87 | 39.32 | 29.94 | 33.06 |
| SOBS[1] | 25.02 | 20.60 | 27.16 | 42.94 | 32.26 | 29.78 | 27.19 | 23.38 |
| LBG[2] | 33.06 | 26.33 | 30.93 | 37.60 | 37.65 | 31.91 | 27.41 | 29.44 |
| MBS[3] | 27.56 | 25.12 | 28.74 | 41.76 | 34.99 | 29.67 | 26.68 | 27.71 |
| PCP[4] | 24.16 | 21.73 | 25.34 | 44.59 | 29.90 | 32.58 | 28.35 | 30.50 |
| OP[5] | 21.08 | 20.12 | 21.23 | 33.13 | 30.75 | 30.52 | 26.45 | 32.50 |
| SSGoDec[6] | 29.89 | 24.19 | 27.50 | 45.91 | 35.43 | 35.42 | 28.56 | 33.02 |
| SBL[7] | 29.72 | 25.00 | 28.61 | 46.02 | 36.32 | 35.83 | 28.62 | 33.04 |
2.Quantitative and Qualitative Results of Foreground Detection
Table 4 : Quantitative foreground separation results on synthetic noisy video clips.
| Office | Canoe | Winter | Boulevard | Shade | Park | Monitor | Cars | Hall | Train | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F-1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | Re | Pre | F1 | |||||||||||||||||||||||||||||||
| Ours | 0.86 | 0.84 | 0.84 | 0.78 | 0.82 | 0.79 | 0.70 | 0.60 | 0.67 | 0.65 | 0.75 | 0.70 | 0.79 | 0.82 | 0.80 | 0.76 | 0.72 | 0.73 | 0.83 | 0.94 | 0.88 | 0.87 | 0.81 | 0.84 | 0.69 | 0.74 | 0.71 | 0.71 | 0.83 | 0.77 | ||||||||||||||||||||||||||||||
| SOBS[1] | 0.69 | 0.70 | 0.67 | 0.54 | 0.70 | 0.58 | 0.19 | 0.41 | 0.18 | 0.41 | 0.67 | 0.48 | 0.65 | 0.82 | 0.70 | 0.39 | 0.80 | 0.56 | 0.66 | 0.98 | 0.78 | 0.53 | 0.88 | 0.66 | 0.59 | 0.70 | 0.64 | 0.25 | 0.52 | 0.34 | ||||||||||||||||||||||||||||||
| LBG[2] | 0.67 | 0.84 | 0.78 | 0.68 | 0.56 | 0.54 | 0.64 | 0.37 | 0.42 | 0.63 | 0.46 | 0.44 | 0.74 | 0.89 | 0.79 | 0.42 | 0.69 | 0.52 | 0.78 | 0.93 | 0.85 | 0.74 | 0.84 | 0.79 | 0.68 | 0.68 | 0.68 | 0.77 | 0.40 | 0.53 | ||||||||||||||||||||||||||||||
| MBS[3] | 0.84 | 0.32 | 0.44 | 0.57 | 0.47 | 0.42 | 0.33 | 0.58 | 0.41 | 0.49 | 0.65 | 0.52 | 0.82 | 0.44 | 0.54 | 0.48 | 0.71 | 0.56 | 0.64 | 0.97 | 0.77 | 0.30 | 0.93 | 0.45 | 0.07 | 0.55 | 0.13 | 0.68 | 0.71 | 0.70 | ||||||||||||||||||||||||||||||
| PCP[4] | 0.52 | 0.80 | 0.60 | 0.35 | 0.30 | 0.32 | 0.44 | 0.40 | 0.41 | 0.50 | 0.72 | 0.60 | 0.68 | 0.73 | 0.69 | 0.66 | 0.73 | 0.70 | 0.70 | 0.86 | 0.77 | 0.68 | 0.81 | 0.74 | 0.53 | 0.72 | 0.61 | 0.76 | 0.66 | 0.71 | ||||||||||||||||||||||||||||||
| OP[5] | 0.32 | 0.58 | 0.43 | 0.20 | 0.32 | 0.26 | 0.30 | 0.42 | 0.37 | 0.45 | 0.35 | 0.40 | 0.58 | 0.47 | 0.53 | 0.62 | 0.51 | 0.57 | 0.68 | 0.69 | 0.68 | 0.62 | 0.70 | 0.74 | 0.66 | 0.71 | 0.69 | 0.68 | 0.82 | 0.71 | ||||||||||||||||||||||||||||||
| SSGoDec[6] | 0.62 | 0.74 | 0.63 | 0.62 | 0.37 | 0.42 | 0.60 | 0.51 | 0.53 | 0.60 | 0.53 | 0.55 | 0.71 | 0.72 | 0.71 | 0.71 | 0.73 | 0.72 | 0.73 | 0.82 | 0.81 | 0.83 | 0.78 | 0.82 | 0.65 | 0.70 | 0.71 | 0.69 | 0.70 | 0.70 | ||||||||||||||||||||||||||||||
| SBL[7] | 0.57 | 0.72 | 0.60 | 0.33 | 0.44 | 0.35 | 0.65 | 0.53 | 0.60 | 0.70 | 0.79 | 0.70 | 0.70 | 0.70 | 0.70 | 0.71 | 0.77 | 0.73 | 0.82 | 0.80 | 0.80 | 0.87 | 0.70 | 0.74 | 0.70 | 0.71 | 0.71 | 0.68 | 0.85 | 0.73 | ||||||||||||||||||||||||||||||

Fig. 6. Visual quality comparison for binary foreground maps on the synthetic noisy video clips: (a) Original noisy frame, (b) Ground truth, (c) our RMAMR model, (d) SOBS [1], (e) LBG [2], (f) MBS [3], (g) PCP[4], (h) OP [5], (i) SSGoDec [6], and (j) SBL[7]. From top to bottom present the 656th frame of Office, the 956th frame of Canoe, the 1936th frame of Winter, the 816th frame of Boulevard, the 481th frame of Shade, the 311th frame of Park, and the 101th frame of Car, the 101th frame of Hall, the 56th frame of Monitor, the 46th frame of Train, respectively.
Click here to download our results and ground truth in Fig.6
1. Xinchen Ye, Jingyu Yang, Xin Sun, Kun Li, Chunping Hou, and Yao Wang, “Foreground-Background Separation From Video Clips via Motion-assisted Matrix Restoration”, Accepted by IEEE Transactions on Circuits and Systems for Video Technology. [pdf] [bib]
2. Jingyu Yang, Xin Sun, Xinchen Ye, and Kun Li, “Background extraction from video sequences via Motion Assisted Matrix Completion”, in Proc. IEEE Int. Conf. Image Processing (ICIP), Paris, France, Oct. 2014. [pdf][bib]
[1] L. Maddalena and A. Petrosino, “A self-organizing approach to background subtraction for visual surveillance applications,” IEEE TIP, vol. 17, no. 7, pp. 1168–1177, 2008.
[2] T. Bouwmans, F. El Baf, and B. Vachon, “Background modeling using mixture of gaussians for foreground detection-a survey,” Recent Patents on Computer Science, vol. 1, no. 3, pp. 219–237, 2008.
[3] J. Yao and J.-M. Odobez, “Multi-layer background subtraction based on color and texture,” in Proc. CVPR, 2007, pp. 1–8.
[4] E. J. Cand`es, X. Li, Y. Ma, and J. Wright, “Robust principal component analysis?” Journal of the ACM (JACM), vol. 58, no. 3, p. 11, 2011.
[5] H. Xu, C. Caramanis, and S. Sanghavi, “Robust pca via outlier pursuit,” in Advances in Neural Information Processing Systems, 2010, pp. 2496–2504.
[6] T. Zhou and D. Tao, “Godec: Randomized low-rank & sparse matrix decomposition in noisy case,” in Proc. ICML, 2011, pp. 33–40.
[7]S. D. Babacan, M. Luessi, R. Molina, and A. K. Katsaggelos, “Sparse bayesian methods for low-rank matrix estimation,” IEEE TSP, vol. 60, no. 8, pp. 3964–3977, 2012.
[8]O. Barnich and M. Van Droogenbroeck, “Vibe: A universal background subtraction algorithm for video sequences,” IEEE TIP, vol. 20, no. 6, pp. 1709–1724, 2011.
[9]A. Manzanera, “Σ-Δ background subtraction and the zipf law,” in Progress in Pattern Recognition, Image Analysis and Applications. Springer, 2007, pp. 42–51.
[10] Z. Zivkovic, “Improved adaptive gaussian mixture model for background subtraction,” in Proc. ICPR, vol. 2, 2004, pp. 28–31.
[11] A. B. Godbehere, A. Matsukawa, and K. Goldberg, “Visual tracking of human visitors under variable-lighting conditions for a responsive audio art installation,” in American Control Conference (ACC). IEEE, 2012, pp. 4305–4312.
[12] M. Hofmann, P. Tiefenbacher, and G. Rigoll, “Background segmentation with feedback: The pixel-based adaptive segmenter,” in Proc. IEEE CVPRW, 2012, pp. 38–43.
[13] Z. Zhao, T. Bouwmans, X. Zhang, and Y. Fang, “A fuzzy background modeling approach for motion detection in dynamic backgrounds,” in Multimedia and Signal Processing, 2012, pp. 177–185.
[14] T. Brox and J. Malik, “Large displacement optical flow: descriptor matching in variational motion estimation,” IEEE TPAMI, vol. 33, no. 3, pp. 500–513, 2011.
