IEEE T-CSVT 2024
Towards Grouping in Large Scenes with Occlusion-aware
Spatio-temporal Transformers
Jinsong Zhang1, Lingfeng Gu1, Yu-Kun Lai2, Xueyang Wang3, Kun Li1*
1 Tianjin University 2 Cardiff University 3 Tsinghua University
* Corresponding author
[Code] [Paper] [PDF]
Abstract
Group detection, especially for large-scale scenes, has many potential applications for public safety and smart cities. Existing methods fail to cope with frequent occlusions in large-scale scenes with multiple people, and are difficult to effectively utilize spatio-temporal information. In this paper, we propose an end-to-end framework, GroupTransformer, for group detection in large-scale scenes. To deal with the frequent occlusions caused by multiple people, we design an occlusion encoder to detect and suppress severely occluded person crops. To explore the potential spatio-temporal relationship, we propose spatio-temporal transformers to simultaneously extract trajectory information and fuse inter-person features in a hierarchical manner. Experimental results on both large-scale and small-scale scenes demonstrate that our method achieves better performance compared with state-of-the-art methods. On large-scale scenes, our method significantly boosts the performance in terms of precision and F1 score by more than 10%. On small-scale scenes, our method still improves the performance of F1 score by more than 5%.
Method
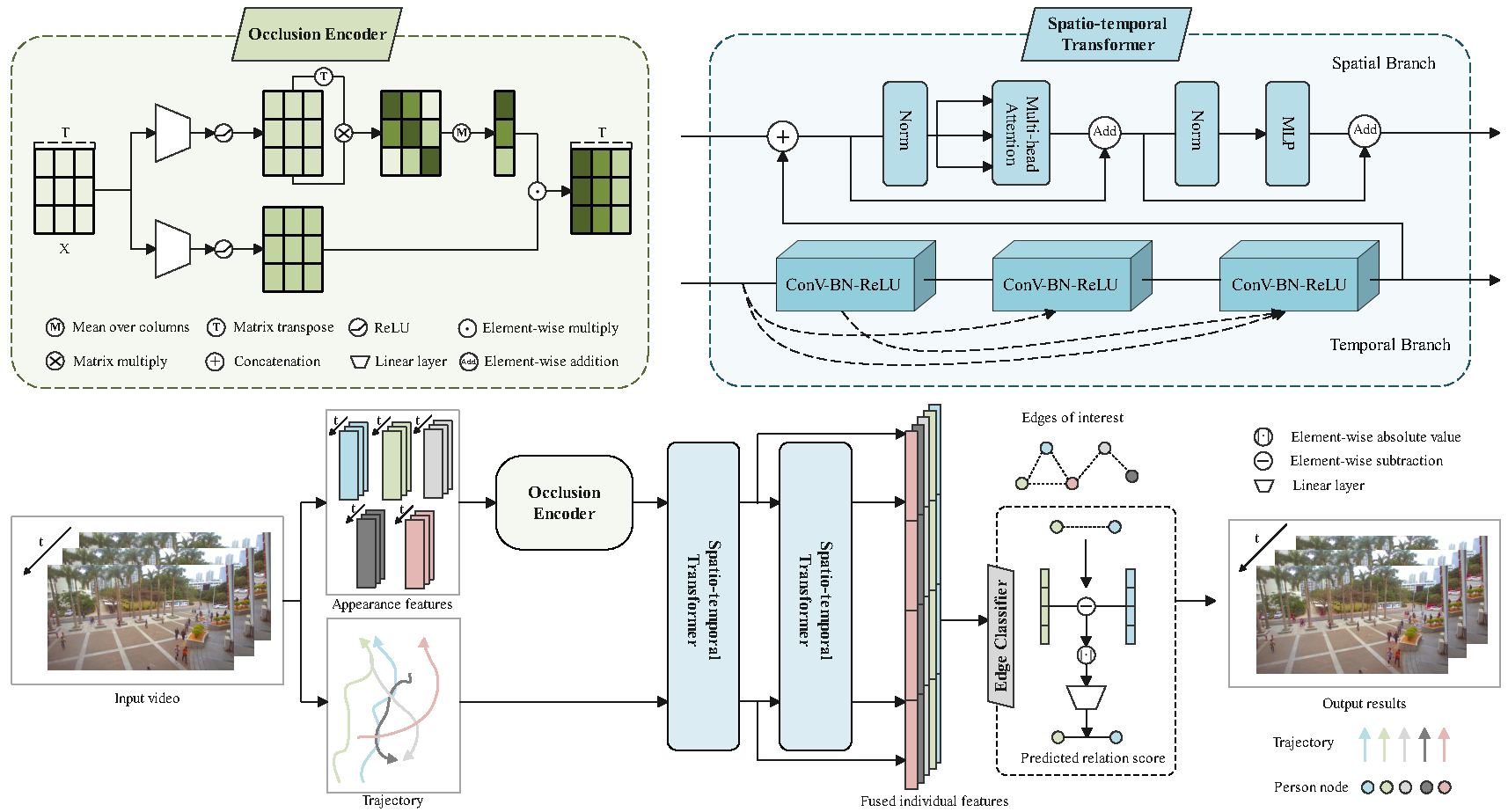
Fig 1. Method overview.
Comparison results

Fig 2. Qualitative results compared with S3R2 on PANDA benchmark.
Dynamic results
Technical Paper

Citation
Jinsong Zhang, Lingfeng Gu, Yu-Kun Lai, Xueyang Wang, Kun Li. "Towards Grouping in Large Scenes with Occlusion-aware Spatio-temporal Transformers," IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 5, pp. 3919-3929, May 2024.
@article{zhang2024tcsvt,
author = {Jinsong Zhang and Lingfeng Gu and Xueyang Wang and Yu-Kun Lai and Kun Li},
title = {Towards Grouping in Large Scenes with Occlusion-aware Spatio-temporal Transformers},
journal = {IEEE Transactions on Circuits and Systems for Video Technology},
year={2024},
volume={34},
number={5},
pages={3919-3929},
}