冯伟
电子邮件:

办公室: 天津大学(北洋园校区)智能与计算学部55楼B417室
个人简介
冯伟,天津大学讲席教授,智能与计算学部副主任,计算机科学与技术学院院长,国家级科技领军人才,重点研发计划项目首席科学家,国家文物局“文物本体表面监测与分析研究”重点科研基地负责人,中国图象图形学学会遥感图像专委会副主任。主要从事计算机视觉、视觉机器人、机器学习领域的研究,发表包括TPAMI、IJCV、TIP、CVPR、ICCV在内的学术论文100余篇,以第一发明人授权专利30项。在开放环境微变视觉感知和多视角视频协同分析方向的研究成果,广泛应用于敦煌、故宫、兵马俑等数十个文化遗产地和博物馆,入选国家“十三五”科技创新成就展,获2024年中国人工智能学会博士学位论文激励计划指导教师,中国国际大学生创新大赛(2023)国赛金奖导师。
实验室长期招聘全职科研人员、博士后及研究生,有意者请邮件联系。
研究兴趣
- 主动视觉定位
- 主动三维场景感知
- 视频分析和通用模式识别
最新动态
2025年6月: 石同凯的研究工作“GReg: Geometry-aware region refinement for sign language video generation”被ICCV 2025录用;
2025年6月: 钱泽坤的研究工作“COVTrack: Continuous open-vocabulary multi-object tracking via adaptive multi-cue fusion”被ICCV 2025录用;项目详见https://github.com/zekunqian/COVTrack
2025年6月: 钱泽坤的研究工作“VOVTrack: Exploring the potentiality in raw videos for open-vocabulary multi-object tracking”被ICCV 2025录用;
2025年6月: 张麒的研究工作“SU-RGS: Relightable 3D gaussian splatting from sparse views under unconstrained illuminations”被ICCV 2025录用;
2025年6月: 章成超的研究工作“FedAGC: Federated continual learning with asymmetric gradient correction”被ICCV 2025录用;
2025年5月: 刘俊康的研究工作“Improving generalization in federated learning with highly heterogeneous data via momentum-based stochastic controlled weight averaging”被ICML 2025录用;
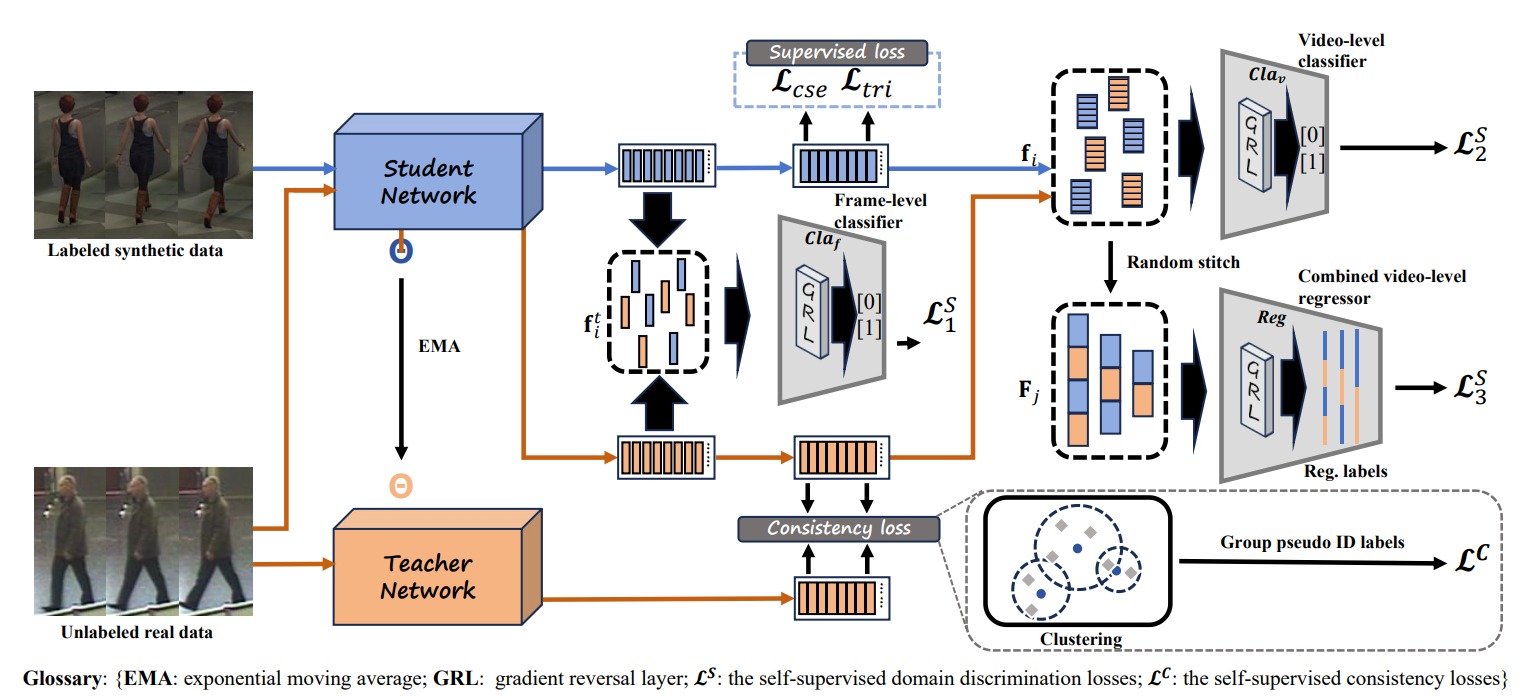
2025年5月: 张向群的研究工作“Synthetic-To-Real Video Person Re-ID”被IEEE Transactions on Information Forensics and Security录用;项目详见https://github.com/XiangqunZhang/UDA_Video_ReID
2025年3月: 张麒的研究工作“Generative Hard Example Augmentation for Semantic Point Cloud Segmentation”被CVPR 2025录用;
2025年3月: 王正阳的研究工作“Dual Semantic Guidence for Open Vocabulary Semantic Segmentation”被CVPR 2025录用;
2025年3月: 尹红梅的研究工作“Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation”被CVPR 2025录用;
2025年2月: 王立凯的研究工作“A New Benchmark and Algorithm for Clothes-Changing Video Person Re-Identification”被IEEE Transactions on Information Forensics and Security录用;项目详见https://github.com/kkw98/CCVReID
2024年11月: 张麒的研究工作“Learning Geometry Consistent Neural Radiance Fields from Sparse and Unposed Views”被ACM MM 2025录用;
2024年9月: 冯伟的研究工作“Unveiling the Power of Self-supervision for Multi-view Multi-human Association”被IEEE Transactions on Pattern Analysis and Machine Intelligence录用;项目详见https://github.com/realgump/MvMHAT
...
学术论文
†为共同第一作者
*为通讯作者
代表性学术论文

Self-validated labeling of markov random fields for image segmentation
Wei Feng, Jiaya Jia, Zhi-Qiang Liu


Selective spatial regularization by reinforcement learned decision making for object tracking
Qing Guo, Ruize Han, Wei Feng*, Zhihao Chen, Liang Wan
Structure-regularized compressive tracking with online data-driven sampling
Qing Guo, Wei Feng*, Ce Zhou, Chi-Man Pun, Bin Wu
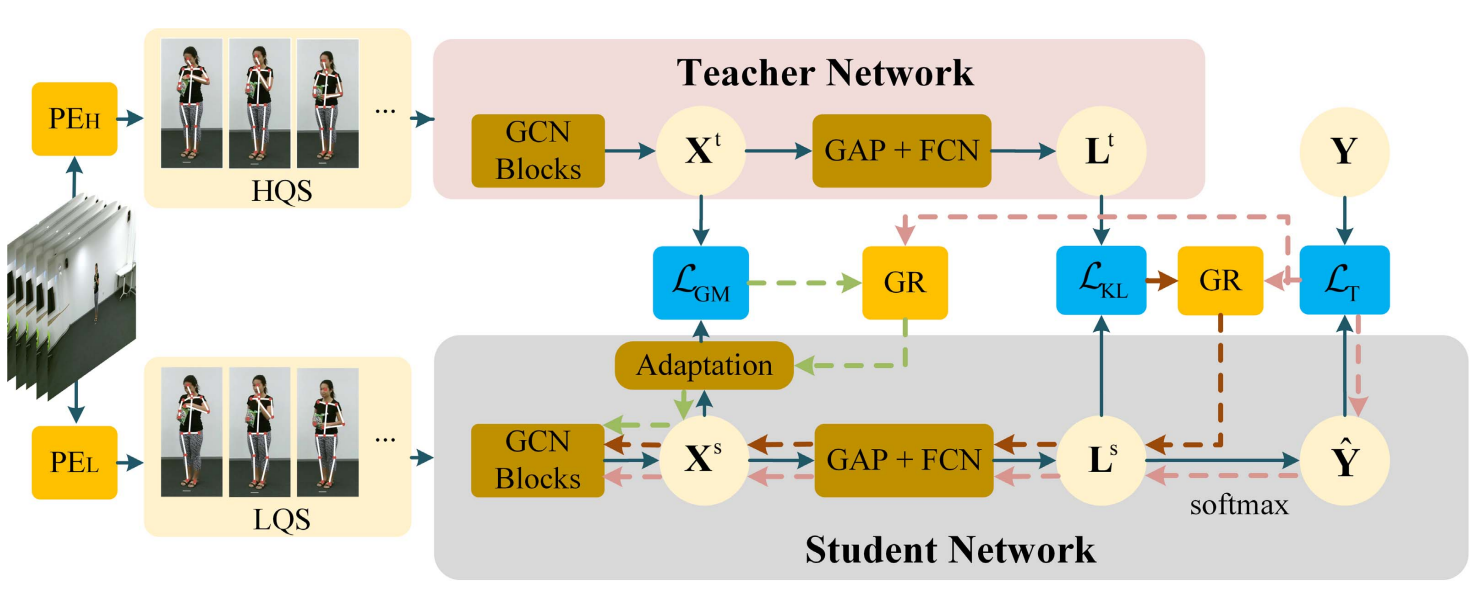
Structural knowledge distillation for efficient skeleton-based action recognition
Cunling Bian, Wei Feng*, Liang Wan, Song Wang*
Fast learning of spatially regularized and content aware correlation filter for visual tracking
Ruize Han, Wei Feng*, Song Wang

Multiscale blur detection by learning discriminative deep features
Rui Huang, Wei Feng*, Mingyuan Fan, Liang Wan, Jizhou Sun
SPARK: Spatial-aware online incremental attack against visual tracking
Qing Guo, Xiaofei Xie, Felix Juefei-Xu, Lei Ma, Zhongguo Li, Wanli Xue, Wei Feng*, Yang Liu
Exploring the effects of blur and deblurring to visual object tracking
Qing Guo, Wei Feng, Ruijun Gao, Yang Liu, Song Wang
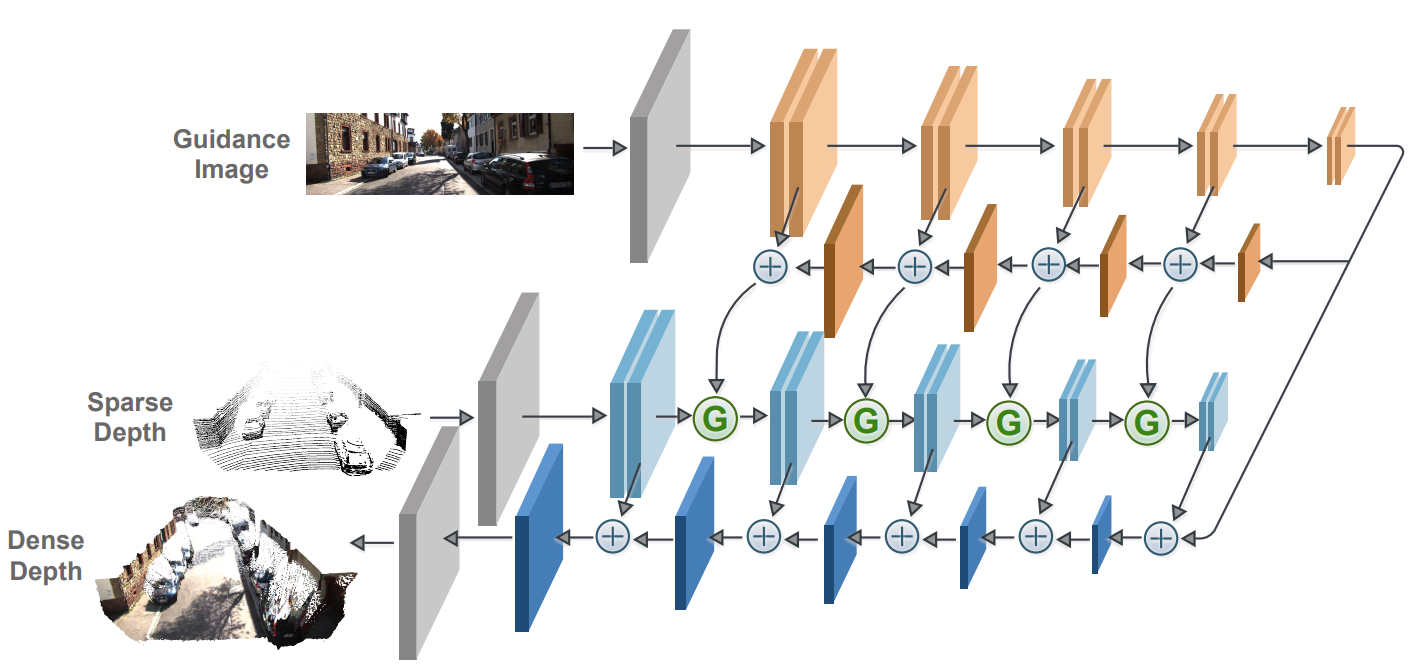

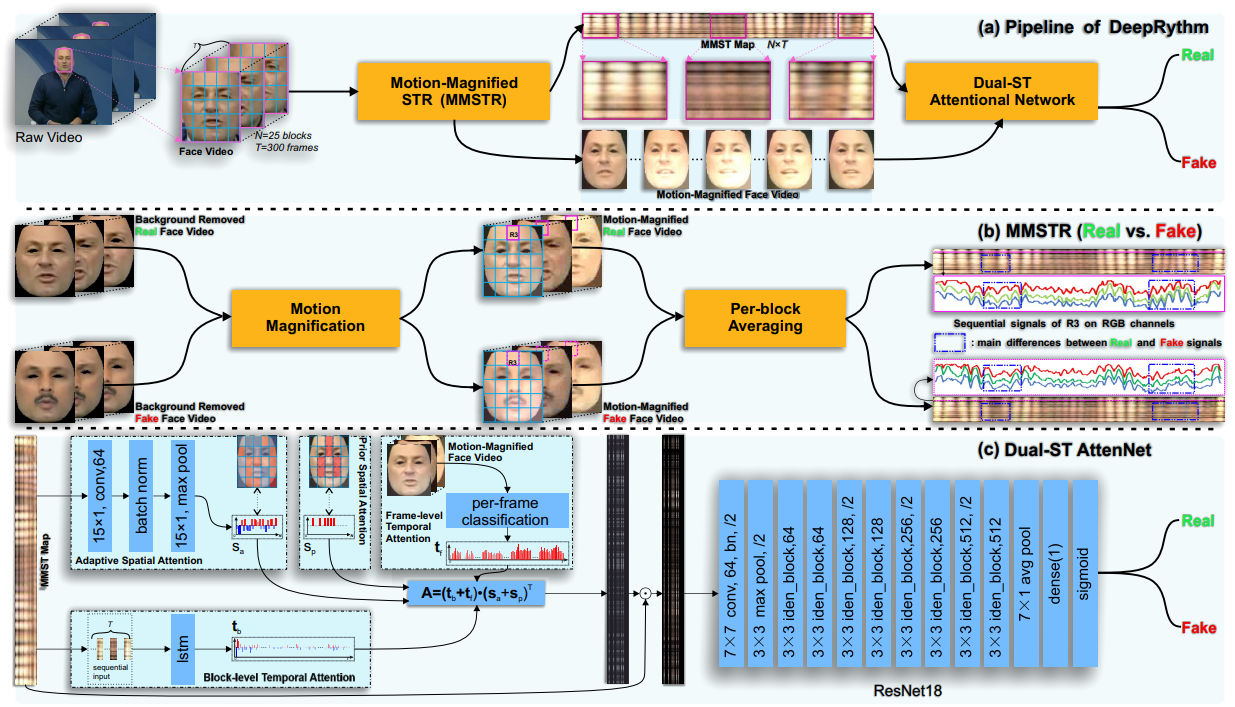
Deeprhythm: Exposing deepfakes with attentional visual heartbeat rhythms
Hua Qi, Qing Guo, Felix Juefei-Xu, Xiaofei Xie, Lei Ma, Wei Feng, Yang Liu, Jianjun Zhao
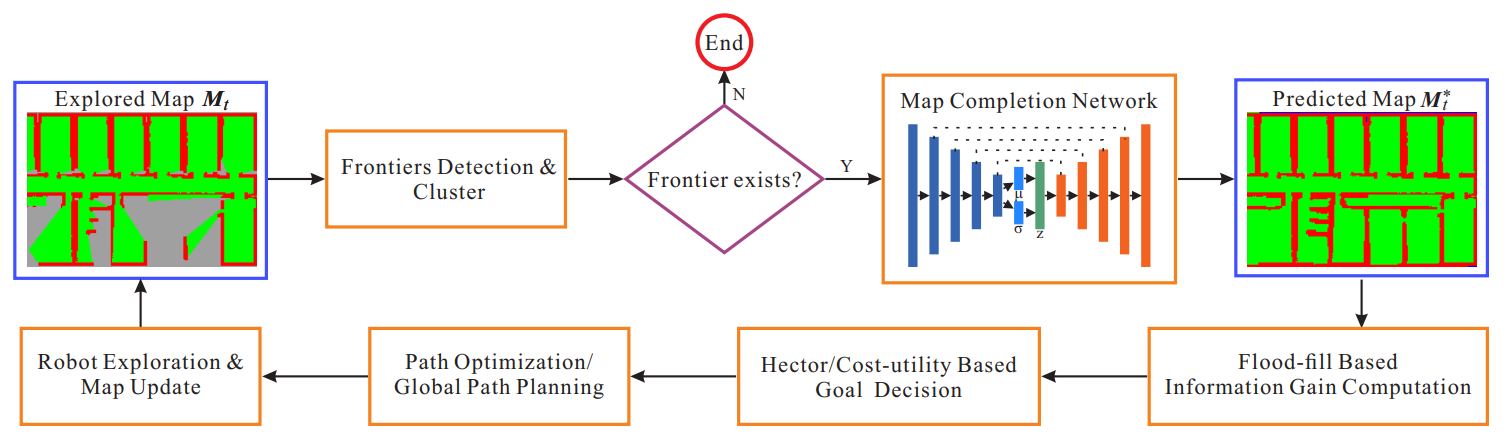
Learned map prediction for enhanced mobile robot exploration
Rakesh Shrestha, Fei-Peng Tian, Wei Feng, Ping Tan, Richard Vaughan
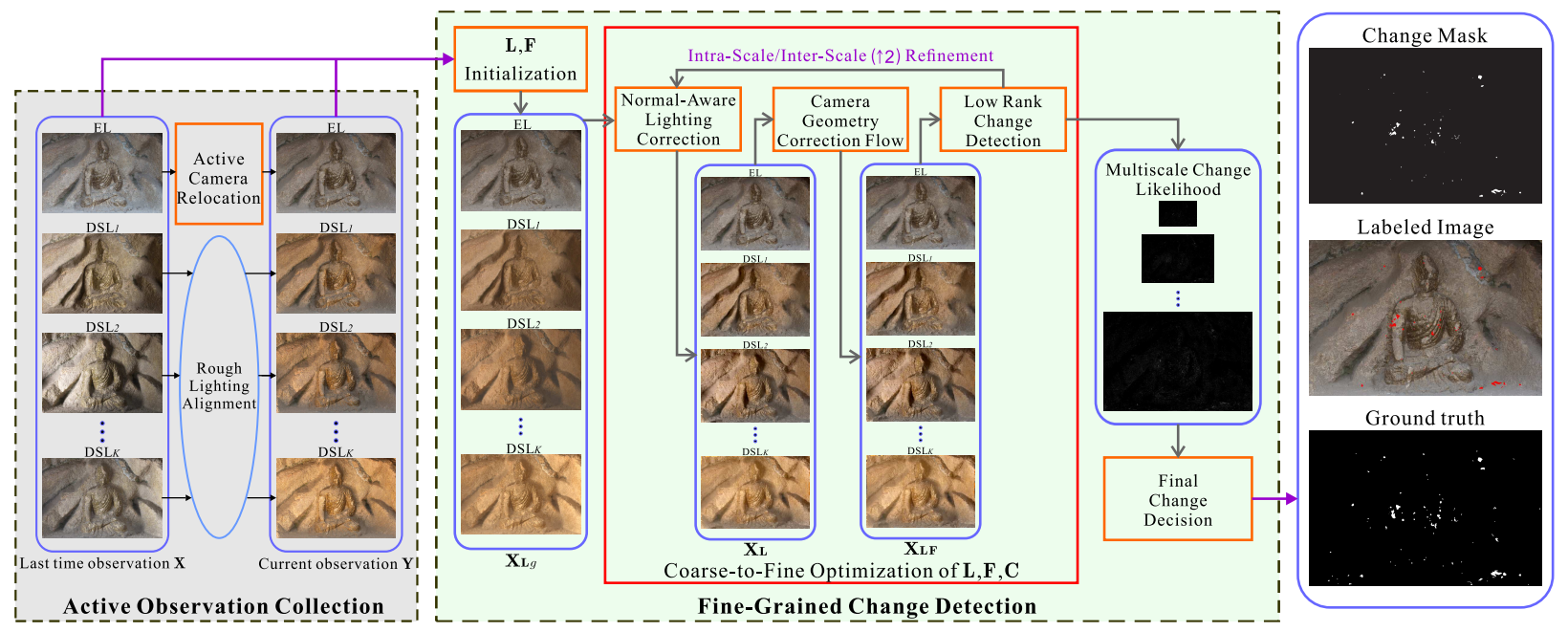
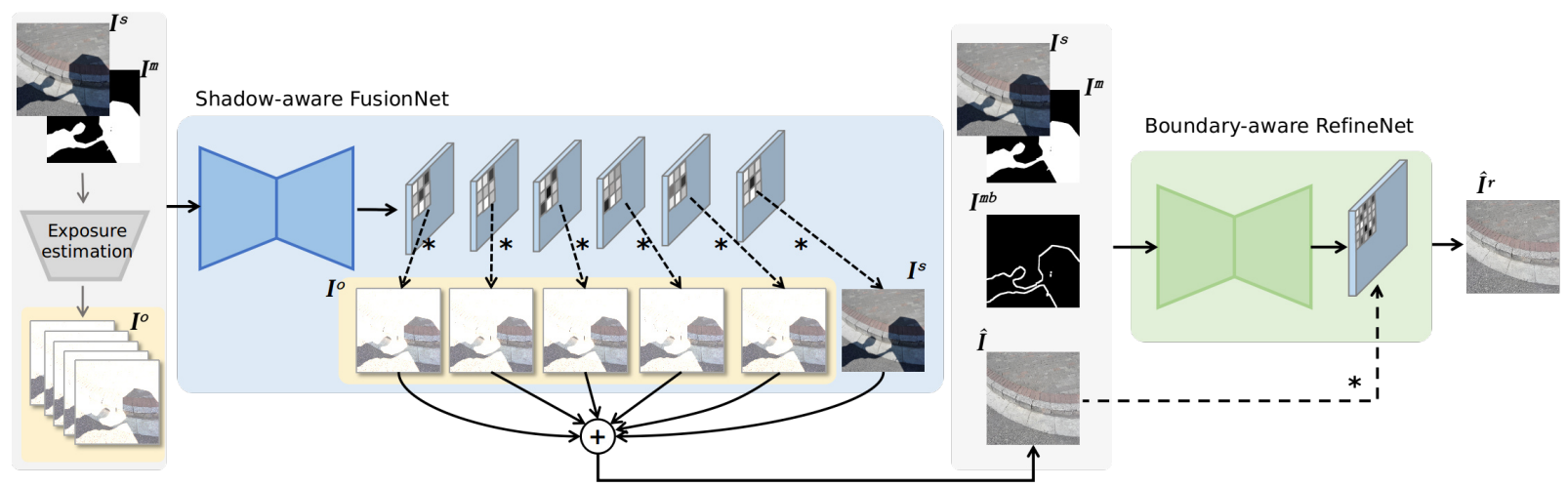
Fine-grained change detection of misaligned scenes with varied illuminations
Wei Feng*, Fei-Peng Tian, Qian Zhang, Nan Zhang, Liang Wan, Jizhou Sun
Content-related spatial regularization for visual object tracking
Ruize Han†, Qing Guo†, Wei Feng*
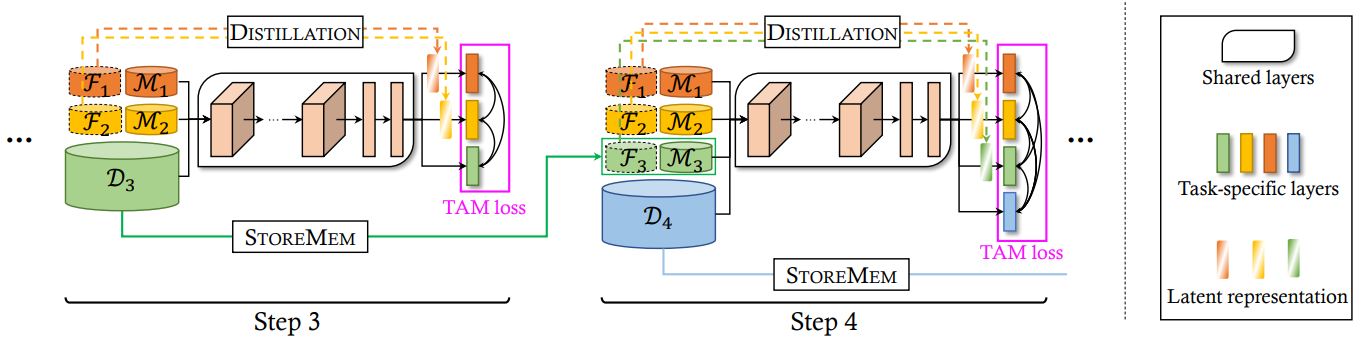
Multi-Domain Multi-Task Rehearsal for Lifelong Learning
Fan Lyu, Shuai Wang, Wei Feng*, Zihan Ye, Fuyuan Hu, Song Wang
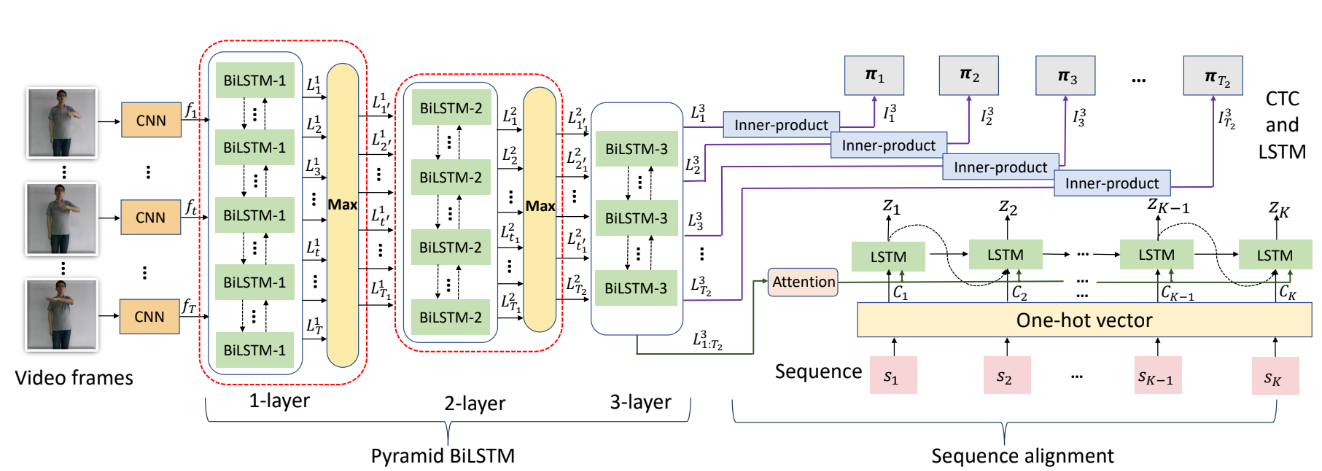
Key action and joint CTC-attention based sign language recognition
Haibo Li, Liqing Gao, Ruize Han, Liang Wan, Wei Feng*
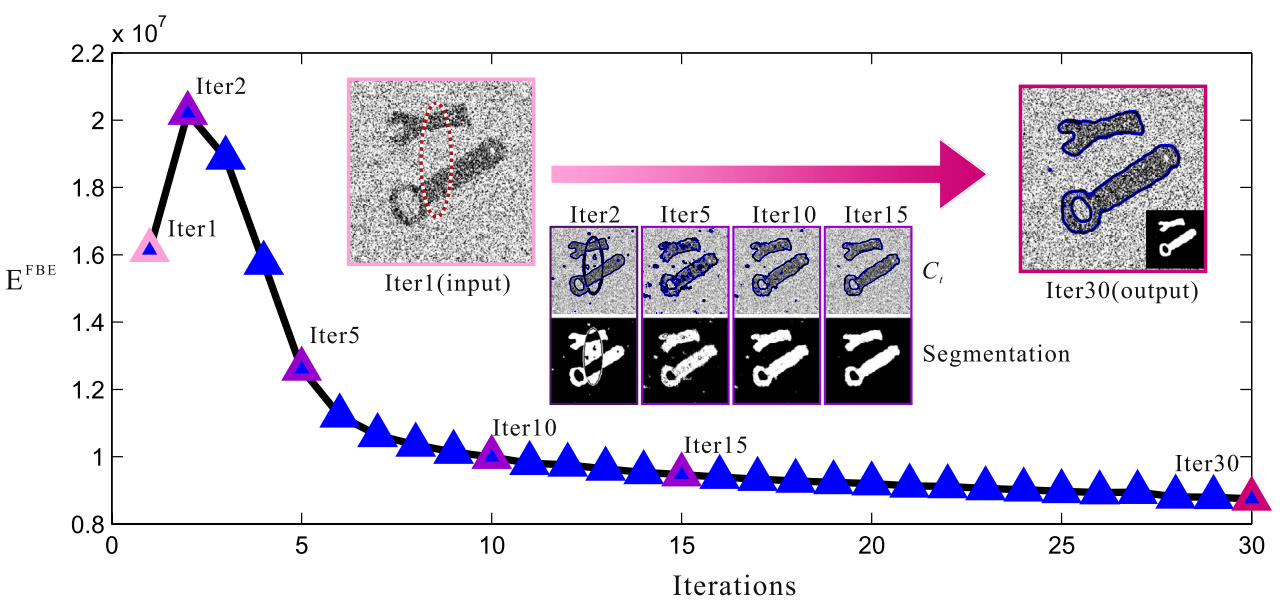
Frequency-tuned active contour model
Qing Guo, Shuifa Sun, Xuhong Ren, Fangmin Dong, Bruce Zhi Gao, Wei Feng*
2025年
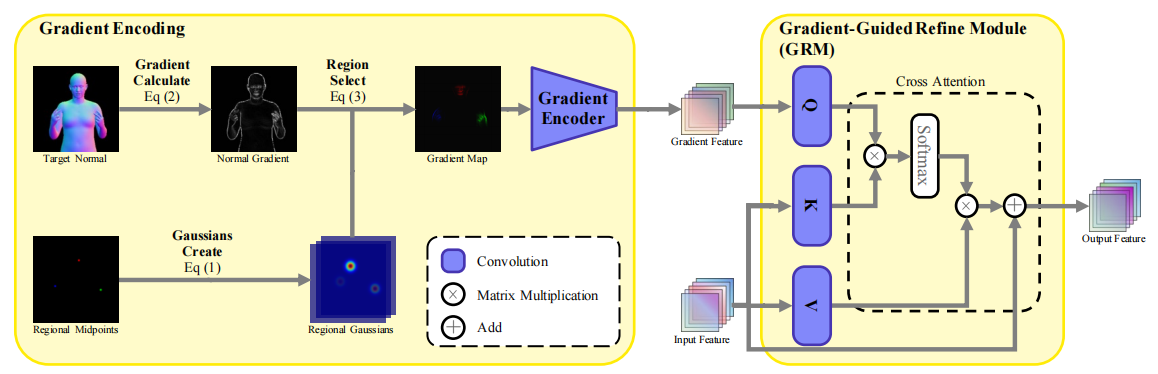
GReg: Geometry-aware region refinement for sign language video generation
Tongkai Shi, Lianyu Hu, Fanhua Shang, Liqing Gao, Wei Feng*
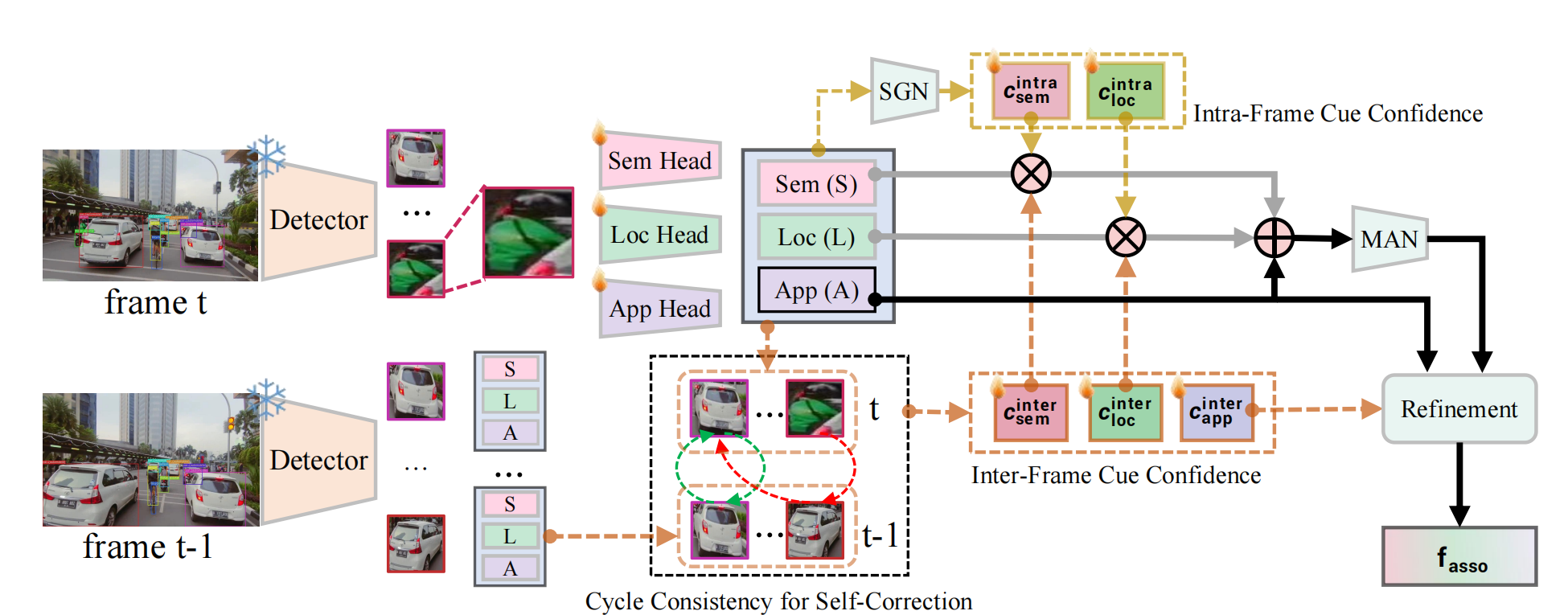
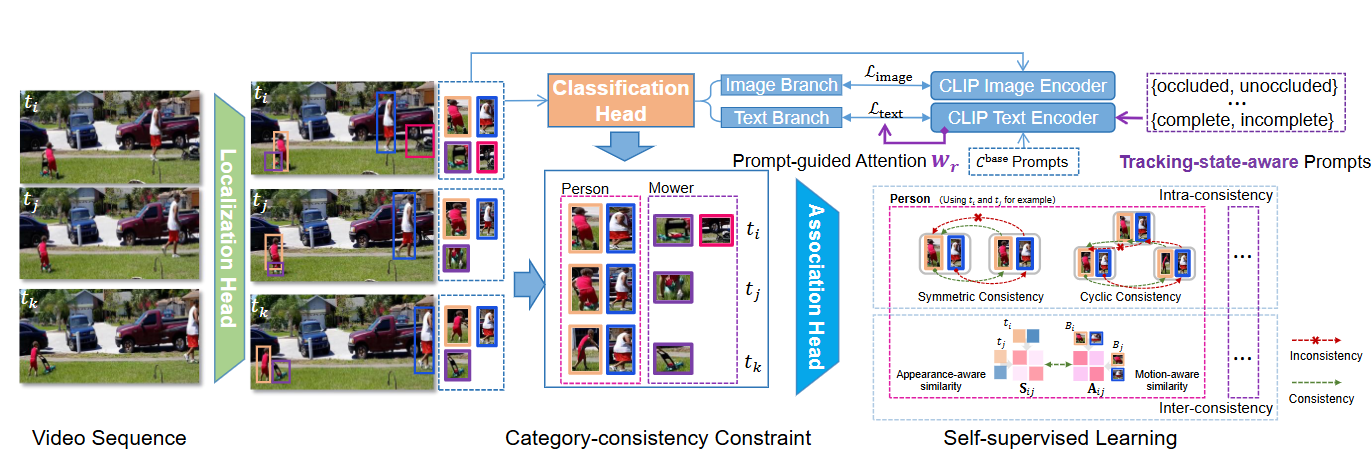
VOVTrack: Exploring the potentiality in raw videos for open-vocabulary multi-object tracking
Zekun Qian, Ruize Han, Junhui Hou, Linqi Song, Wei Feng*
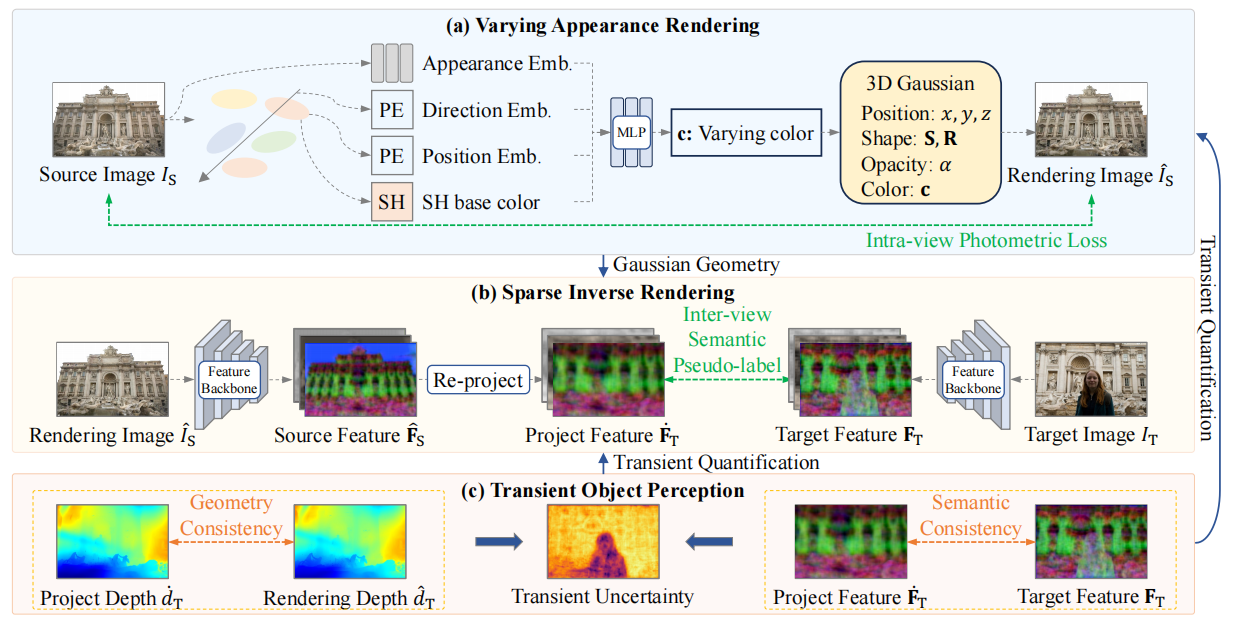
SU-RGS: Relightable 3D gaussian splatting from sparse views under unconstrained illuminations
Qi Zhang, Chi Huang, Qian Zhang, Nan Li, Wei Feng*
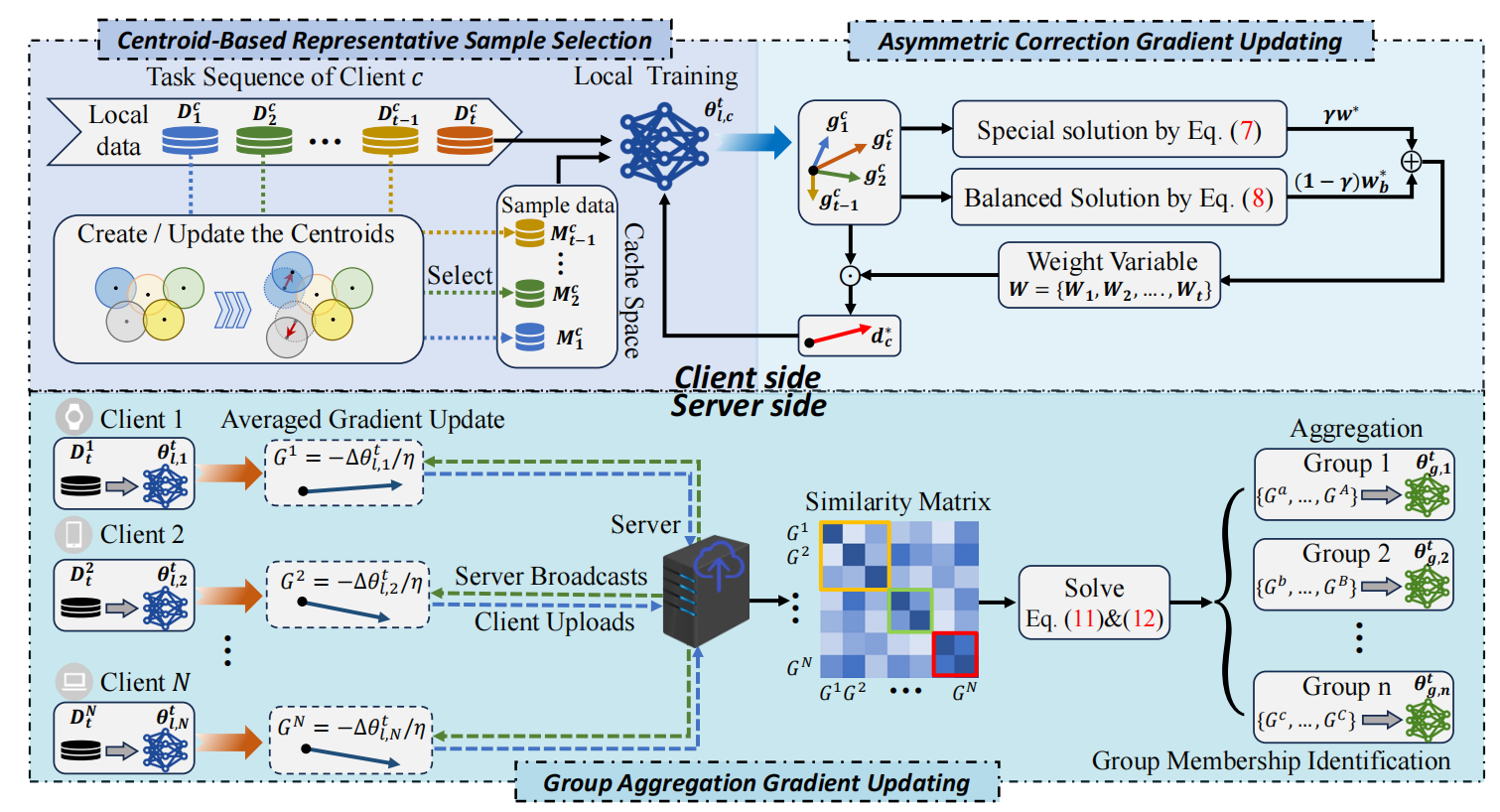
FedAGC: Federated continual learning with asymmetric gradient correction
Chengchao Zhang, Fanhua Shang*, Hongying Liu,Liang Wan, Wei Feng
2024年
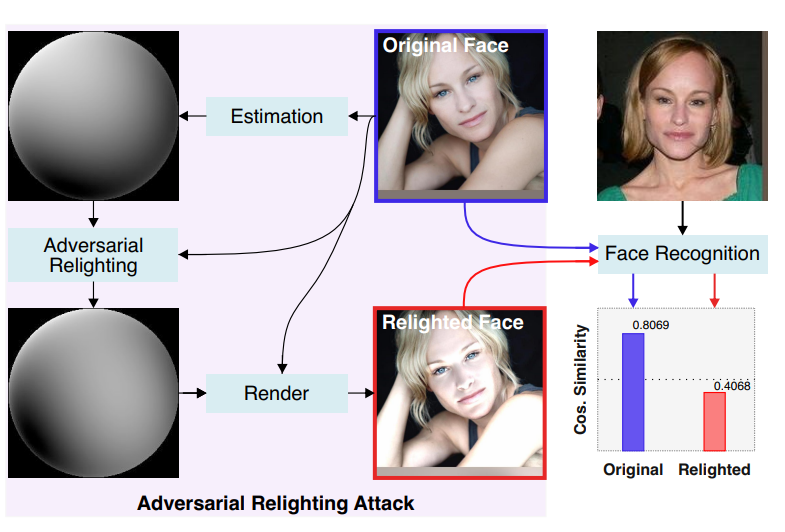
Adversarial relighting against face recognition
Qian Zhang, Qing Guo, Ruijun Gao, Felix Juefei-Xu, Hongkai Yu, Wei Feng*
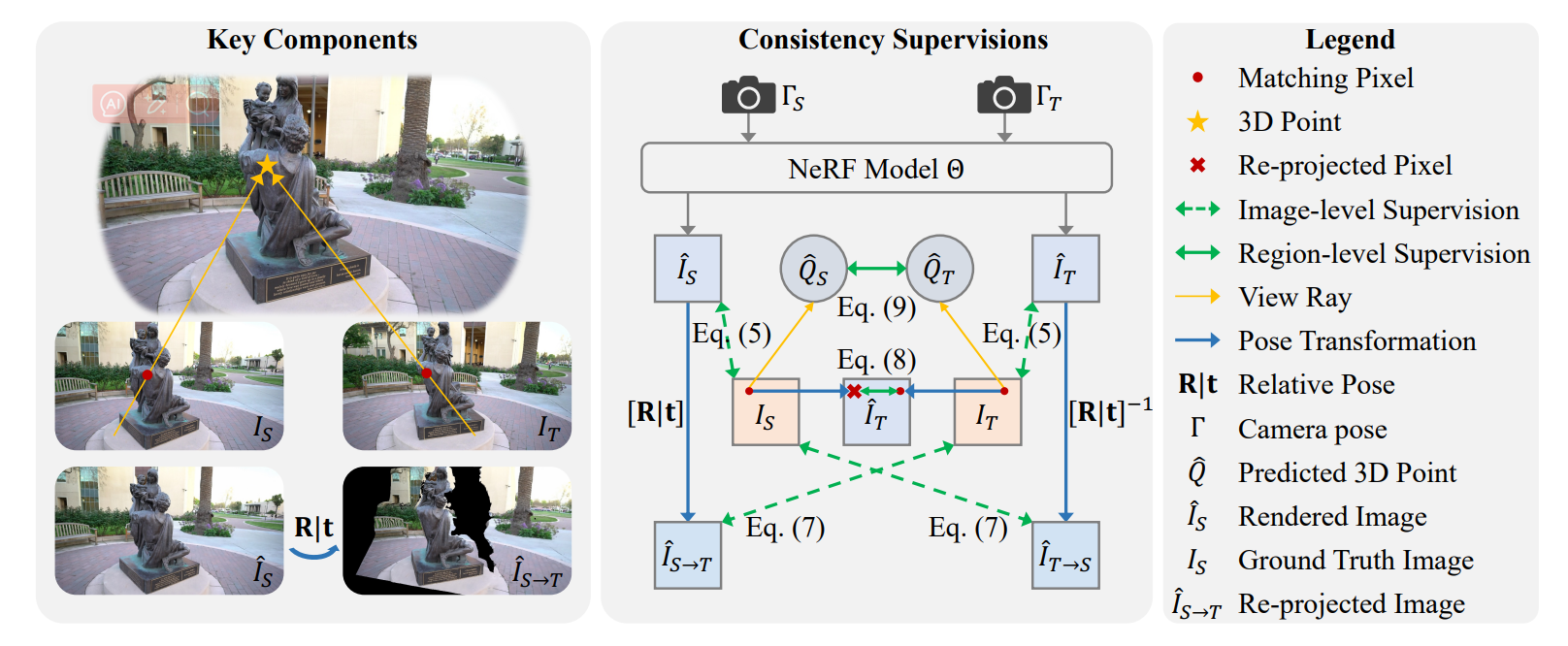
Learning geometry consistent neural radiance fields from sparse and unposed views
Qi Zhang, Chi Huang, Qiang Zhang, Nan Li, Wei Feng*
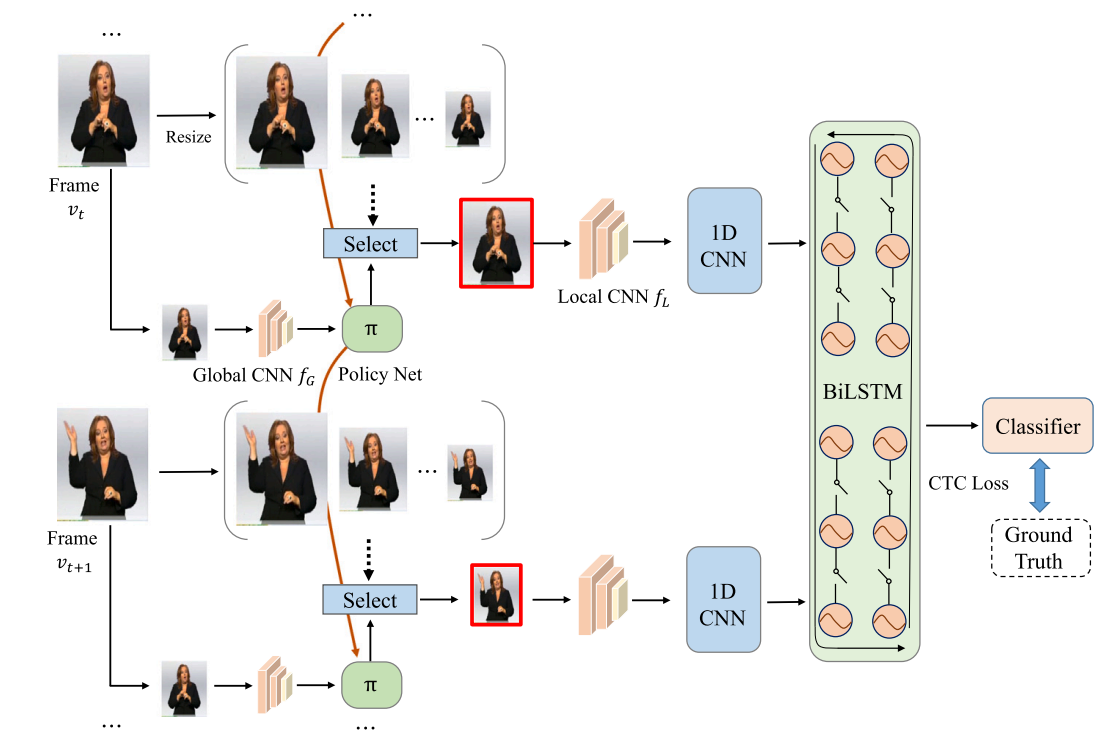
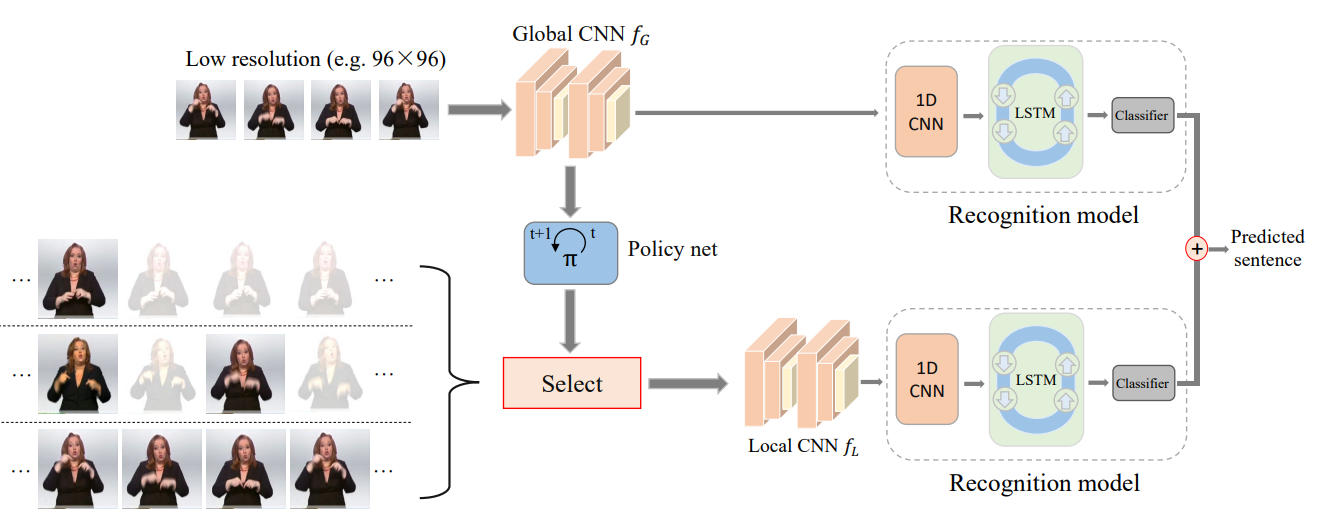
Scalable frame resolution for efficient continuous sign language recognition
Lianyu Hu, Liqing Gao, Zekang Liu, Wei Feng*
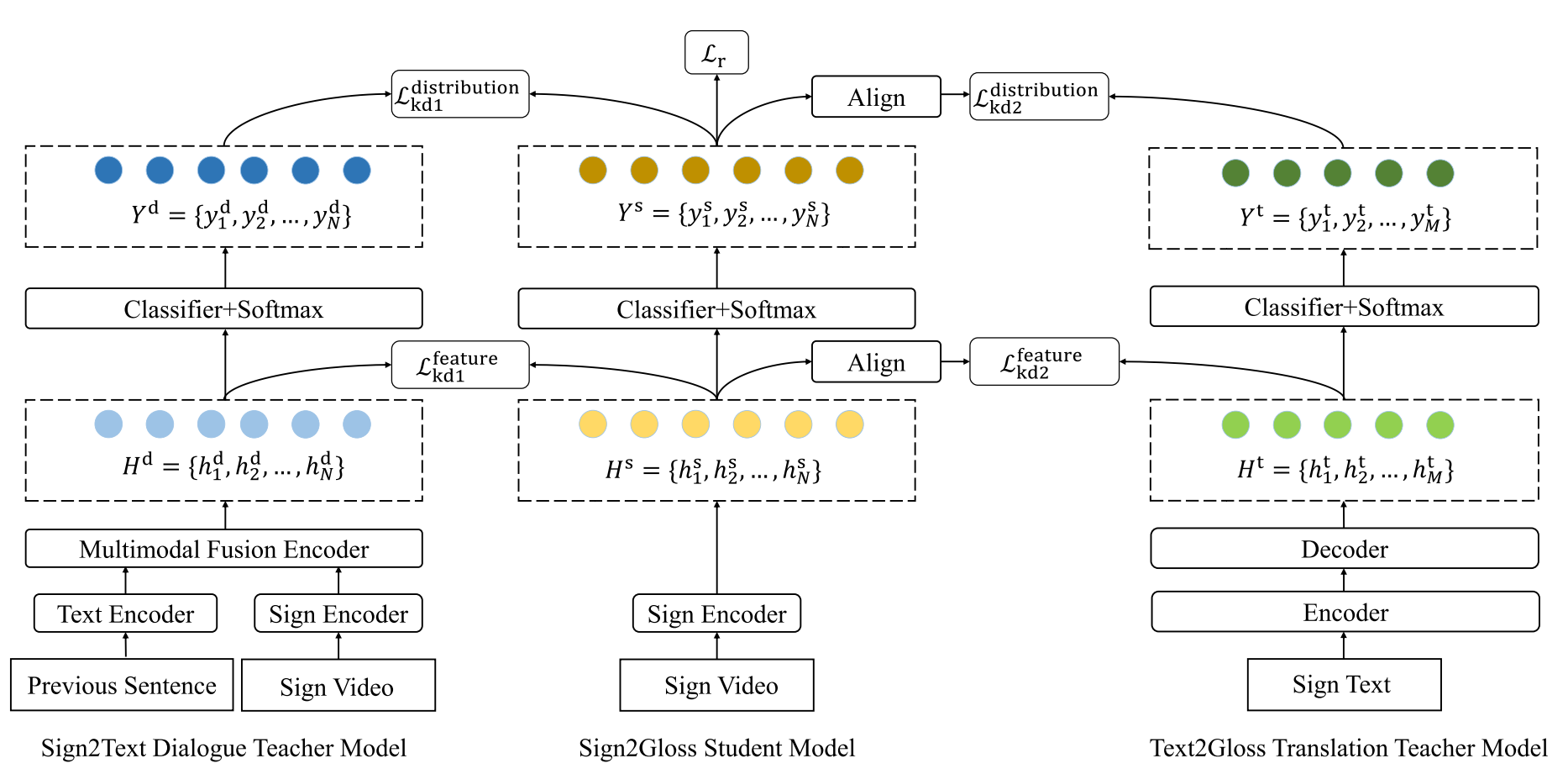
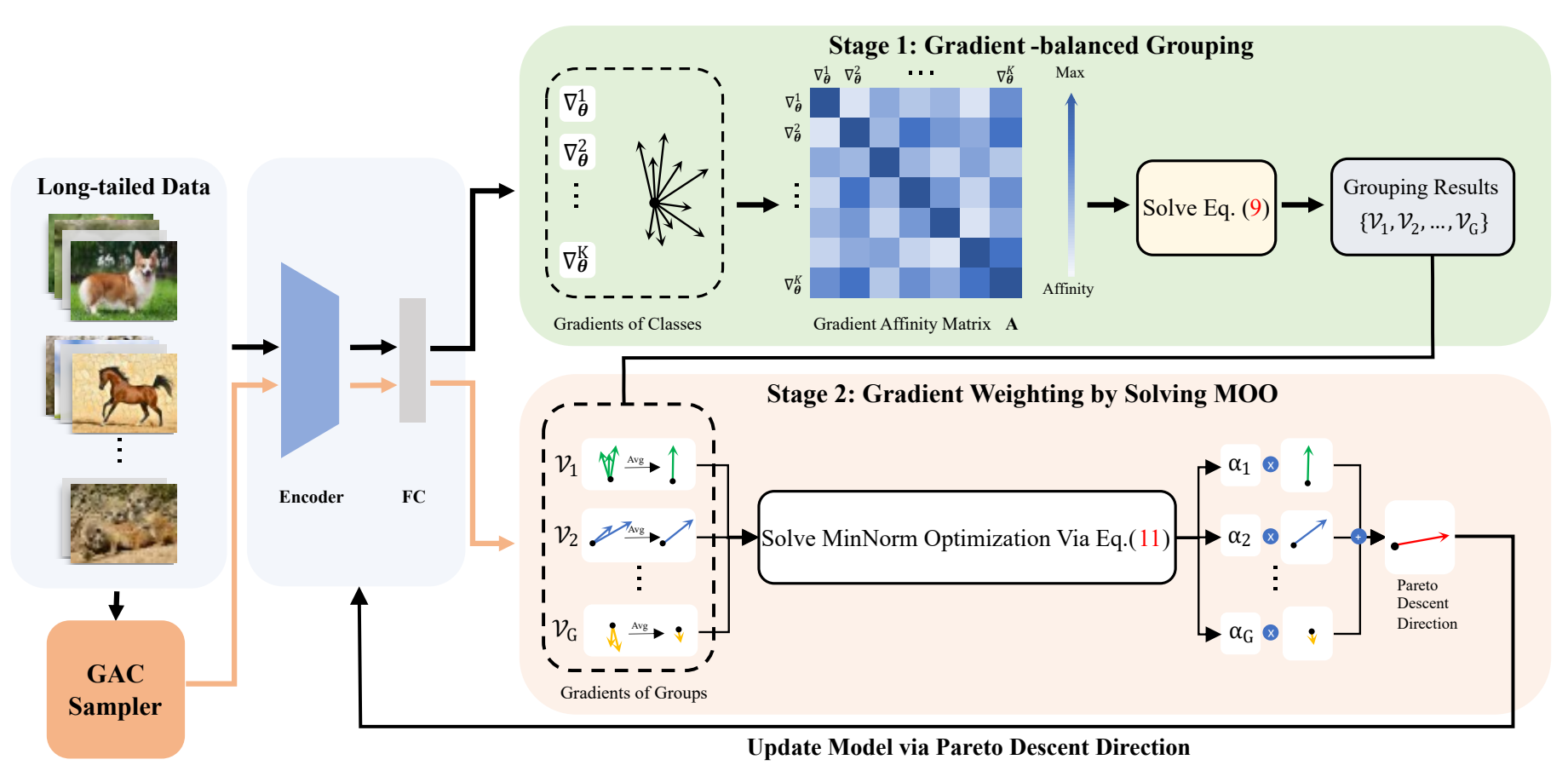
2023年

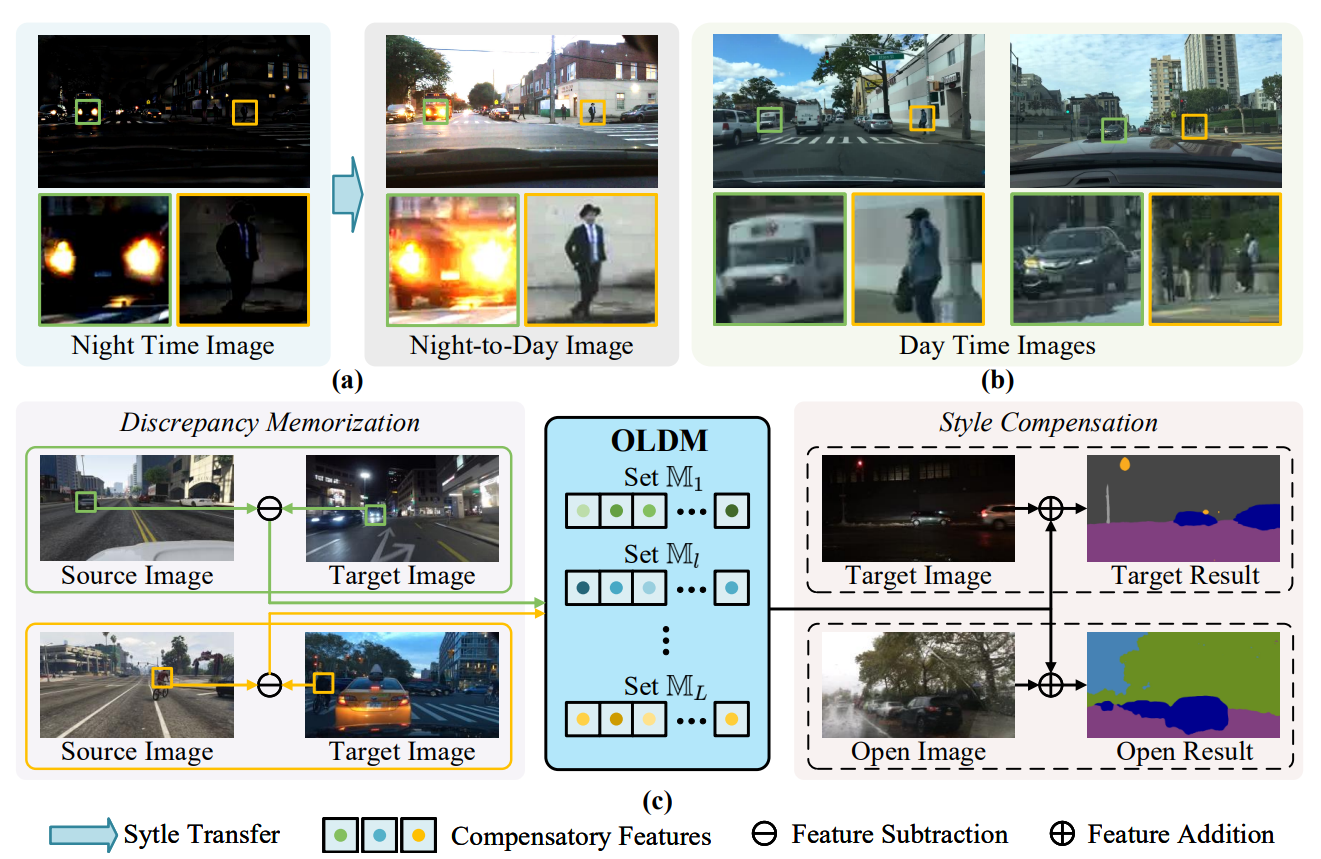
Open compound domain adaptation with object style compensation for semantic segmentation
Tingliang Feng†, Hao Shi†, Xueyang Liu, Wei Feng, Liang Wan, Yanlin Zhou, Di Lin*
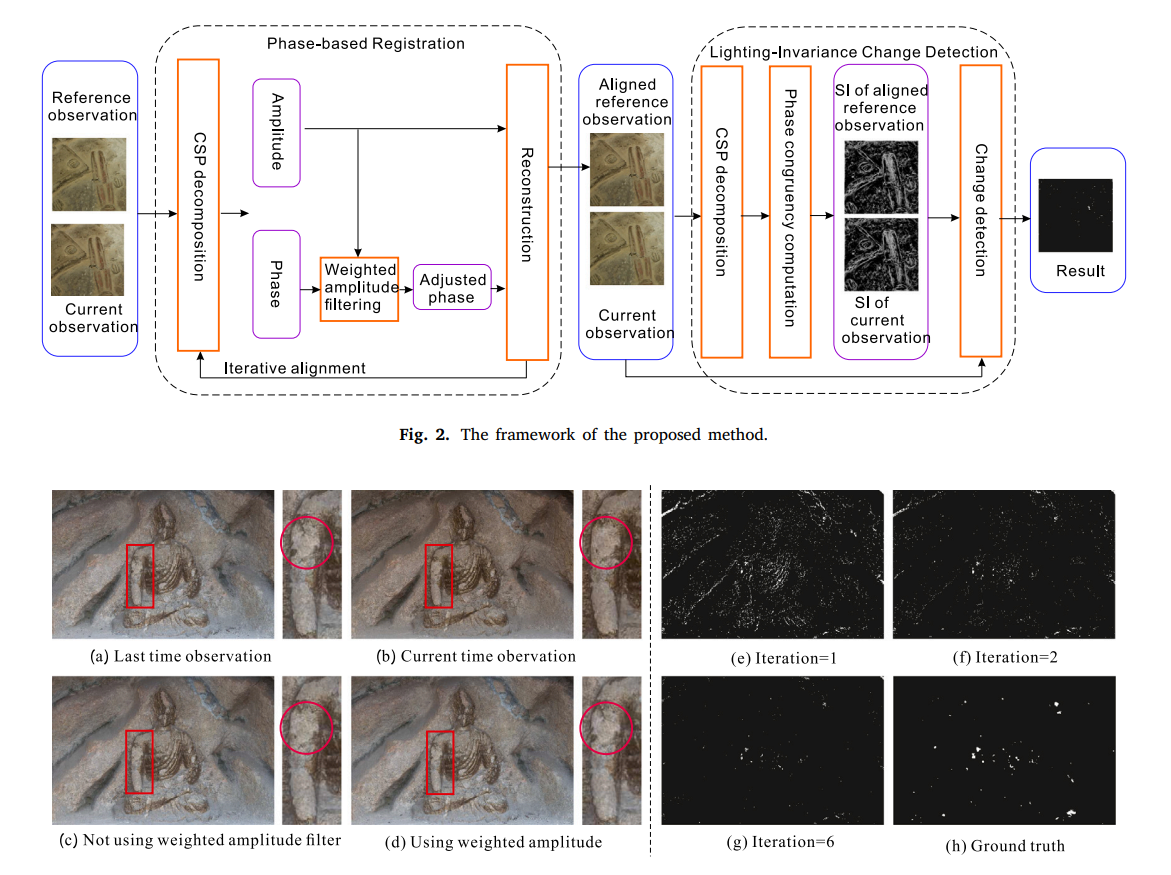
Phase-based fine-grained change detection
Xuzhi Wang, Liang Wan*, Di Lin, Wei Feng