Wei Feng
Chair Professor, Visual Intelligence Lab, College of Intelligence and Computing, Tianjin University
Email:

Office: 55 Building B417, College of Intelligence and Computing, Tianjin University
Home Page: https://cic.tju.edu.cn/info/1067/1913.htm
Personal Profile
Wei Feng, chair professor of Tianjin University, deputy director of the College of Intelligence and Computing, dean of the School of Computer Science and Technology, national science and technology leading talents, chief scientist of key research and development Program, person in charge of the key research base of "SMARC" of the State Administration of Cultural Heritage, deputy director of the Remote Sensing Image Committee of the Chinese Society of Image and Graphics.
His major research interests are active robotic vision and visual intelligence, specifically including active camera relocalization and lighting recurrence, general Markov Random Fields modeling, energy minimization, active 3D scene perception, SLAM, and video understanding. He has published more than 100 academic papers including TPAMI, IJCV, TIP, CVPR and ICCV, and 30 patents authorized by the first inventor. The research results in the direction of fine-grained change detection and multi-view video collaborative analysis in open environment have been widely used in dozens of cultural heritage sites and museums such as Dunhuang, Forbidden City, Terracotta Warriors, etc. They have been selected for the National "13th Five-Year Plan" scientific and Technological Innovation Achievement Exhibition. He won the 2024 Doctoral Thesis Incentive Plan of Chinese Artificial Intelligence Society and the gold medal of National Competition of China International University Students Innovation Competition (2023).
The laboratory is recruiting full-time researchers, postdoctoral researchers, and graduate students. Interested parties are encouraged to contact us via email.
Research Interests
- Active Visual Localization
- Active 3D Scene Perception
- Video Analysis and General Pattern Recognition
Recent News
June 2025: Tongkai Shi's research work "GReg: Geometry-aware region refinement for sign language video generation" was accepted by ICCV 2025;
June 2025: Zekun Qian's research work "COVTrack: Continuous open-vocabulary multi-object tracking via adaptive multi-cue fusion" was accepted by ICCV 2025; Please visit https://github.com/zekunqian/COVTrack for more details.
June 2025: Zekun Qian's research work "VOVTrack: Exploring the potentiality in raw videos for open-vocabulary multi-object tracking" was accepted by ICCV 2025;
June 2025: Qi Zhang's research work "SU-RGS: Relightable 3D gaussian splatting from sparse views under unconstrained illuminations" was accepted by ICCV 2025;
June 2025: Chengchao Zhang's research work "FedAGC: Federated continual learning with asymmetric gradient correction" was accepted by ICCV 2025;
May 2025: Junkang Liu's research work "Improving generalization in federated learning with highly heterogeneous data via momentum-based stochastic controlled weight averaging" was accepted by ICML 2025;
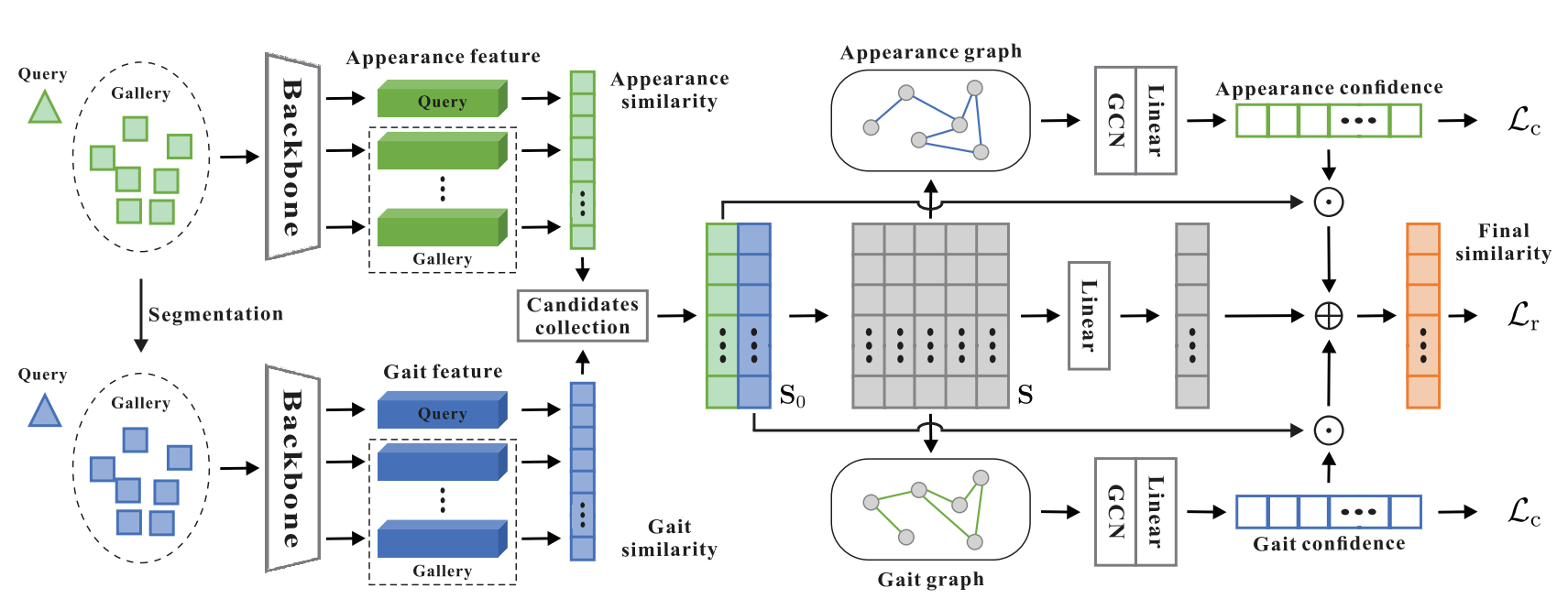
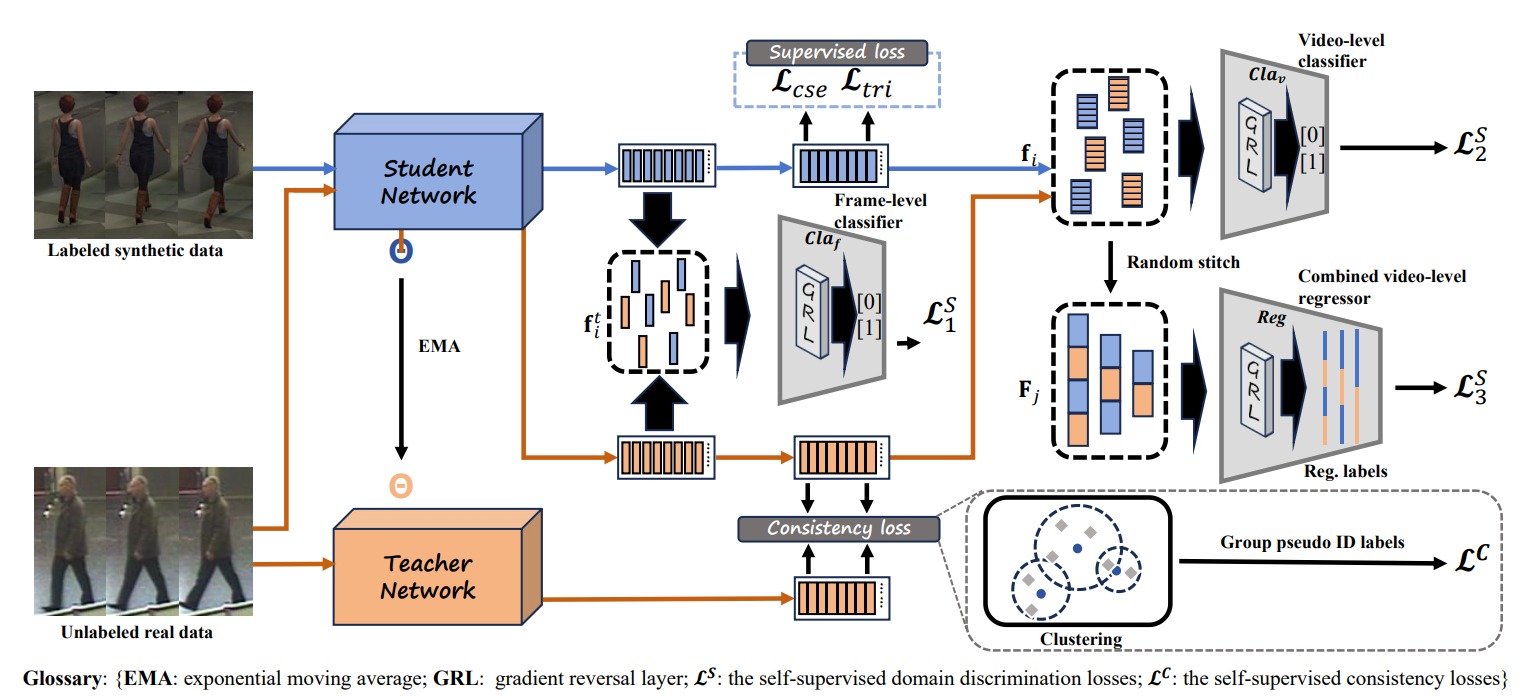
May 2025: Xiangqun Zhang's research work "Synthetic-To-Real Video Person Re-ID" has been published in IEEE Transactions on Information Forensics and Security; Please visit https://github.com/XiangqunZhang/UDA_Video_ReID for more details.
March 2025: Qi Zhang's research work "Generative Hard Example Augmentation for Semantic Point Cloud Segmentation" was accepted by CVPR 2025;
March 2025: Zhengyang Wang's research work "Dual Semantic Guidence for Open Vocabulary Semantic Segmentation" was accepted by CVPR 2025;
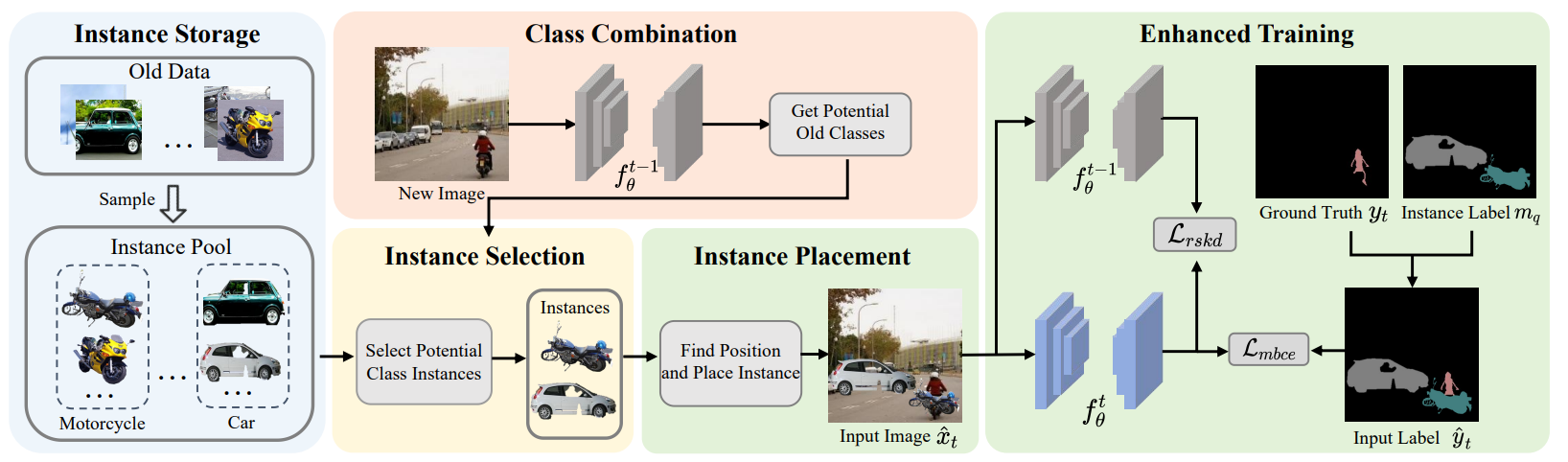
March 2025: Hongmei Yin's research work "Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation" was accepted by CVPR 2025;
February 2025: Likai Wang's research work "A New Benchmark and Algorithm for Clothes-Changing Video Person Re-Identification" has been published in IEEE Transactions on Information Forensics and Security; Please visit https://github.com/kkw98/CCVReID for more details.
November 2024: Qi Zhang's research work "Learning Geometry Consistent Neural Radiance Fields from Sparse and Unposed Views" was accepted by ACM MM 2025;
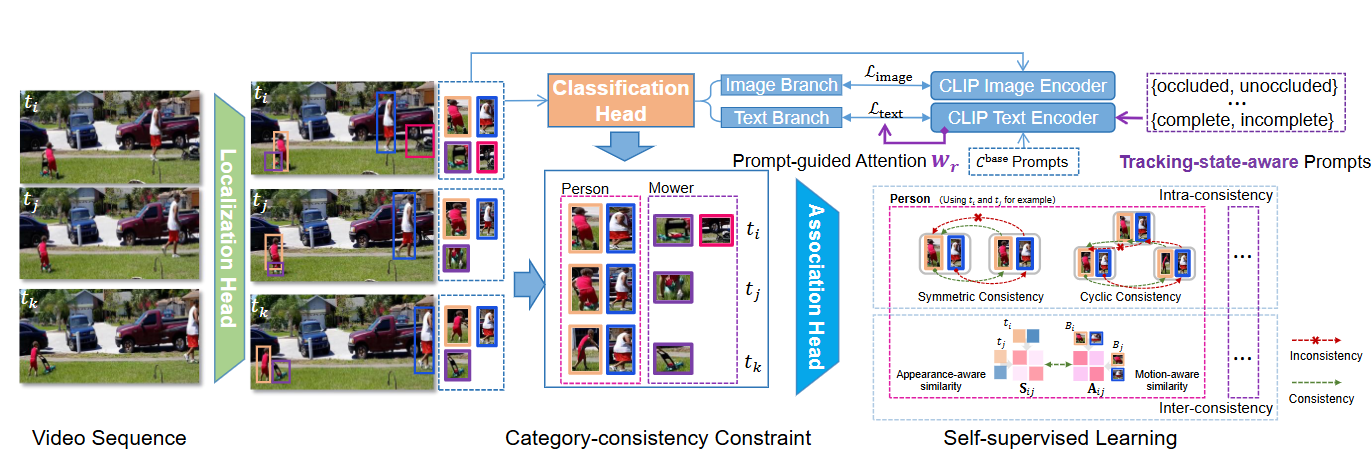
September 2024: Wei Feng's research work "Unveiling the Power of Self-supervision for Multi-view Multi-human Association" has been published in IEEE Transactions on Pattern Analysis and Machine Intelligence; Please visit https://github.com/realgump/MvMHAT for more details.
...
Publications
† indicates joint first authors
* indicates corresponding author
Selected publications

Self-validated labeling of markov random fields for image segmentation
Wei Feng, Jiaya Jia, Zhi-Qiang Liu


Selective spatial regularization by reinforcement learned decision making for object tracking
Qing Guo, Ruize Han, Wei Feng*, Zhihao Chen, Liang Wan
Structure-regularized compressive tracking with online data-driven sampling
Qing Guo, Wei Feng*, Ce Zhou, Chi-Man Pun, Bin Wu
Structural knowledge distillation for efficient skeleton-based action recognition
Cunling Bian, Wei Feng*, Liang Wan, Song Wang*
Fast learning of spatially regularized and content aware correlation filter for visual tracking
Ruize Han, Wei Feng*, Song Wang

Multiscale blur detection by learning discriminative deep features
Rui Huang, Wei Feng*, Mingyuan Fan, Liang Wan, Jizhou Sun
SPARK: Spatial-aware online incremental attack against visual tracking
Qing Guo, Xiaofei Xie, Felix Juefei-Xu, Lei Ma, Zhongguo Li, Wanli Xue, Wei Feng*, Yang Liu
Exploring the effects of blur and deblurring to visual object tracking
Qing Guo, Wei Feng, Ruijun Gao, Yang Liu, Song Wang

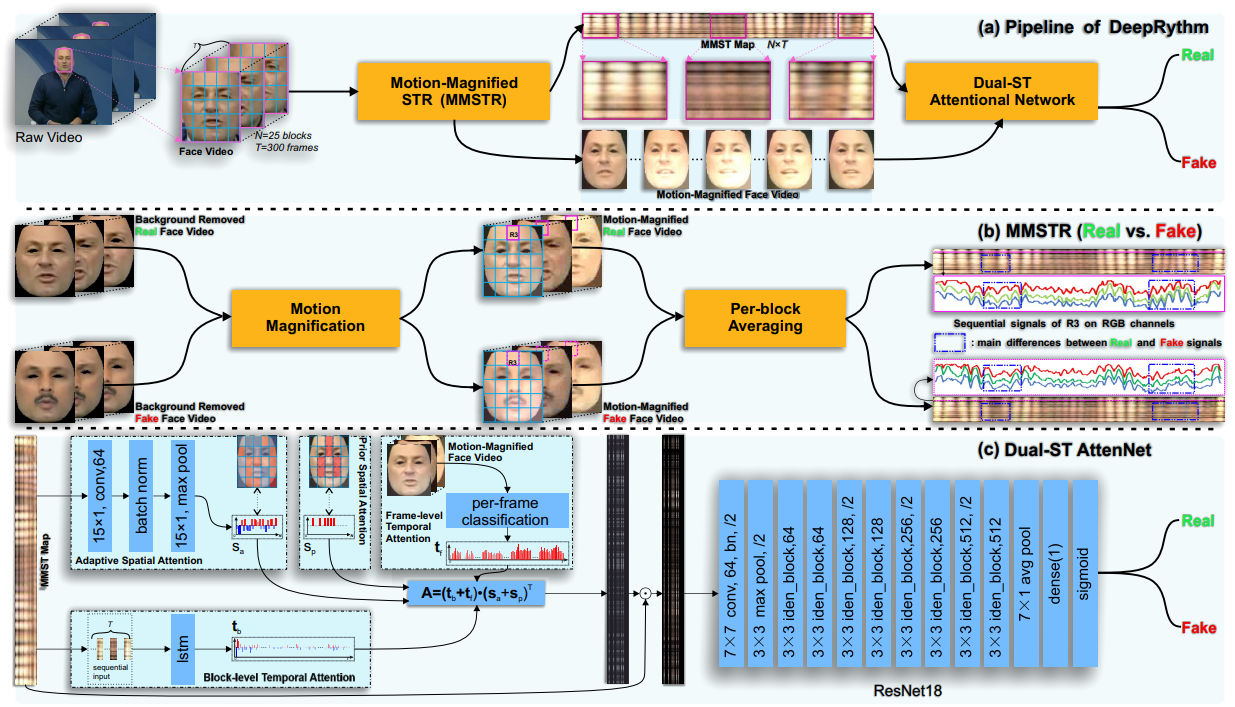
Deeprhythm: Exposing deepfakes with attentional visual heartbeat rhythms
Hua Qi, Qing Guo, Felix Juefei-Xu, Xiaofei Xie, Lei Ma, Wei Feng, Yang Liu, Jianjun Zhao
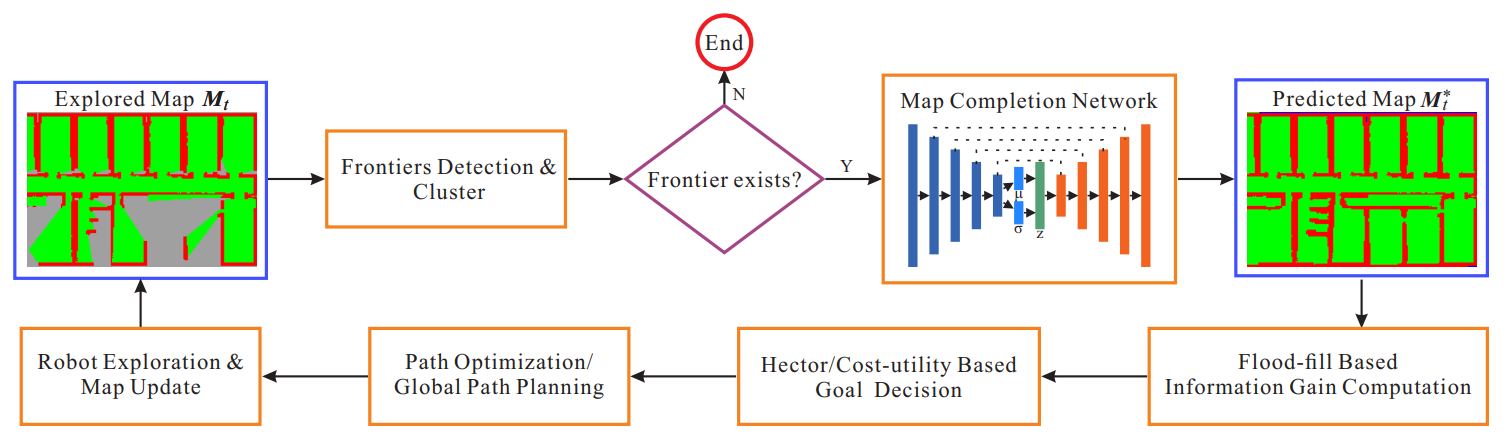
Learned map prediction for enhanced mobile robot exploration
Rakesh Shrestha, Fei-Peng Tian, Wei Feng, Ping Tan, Richard Vaughan
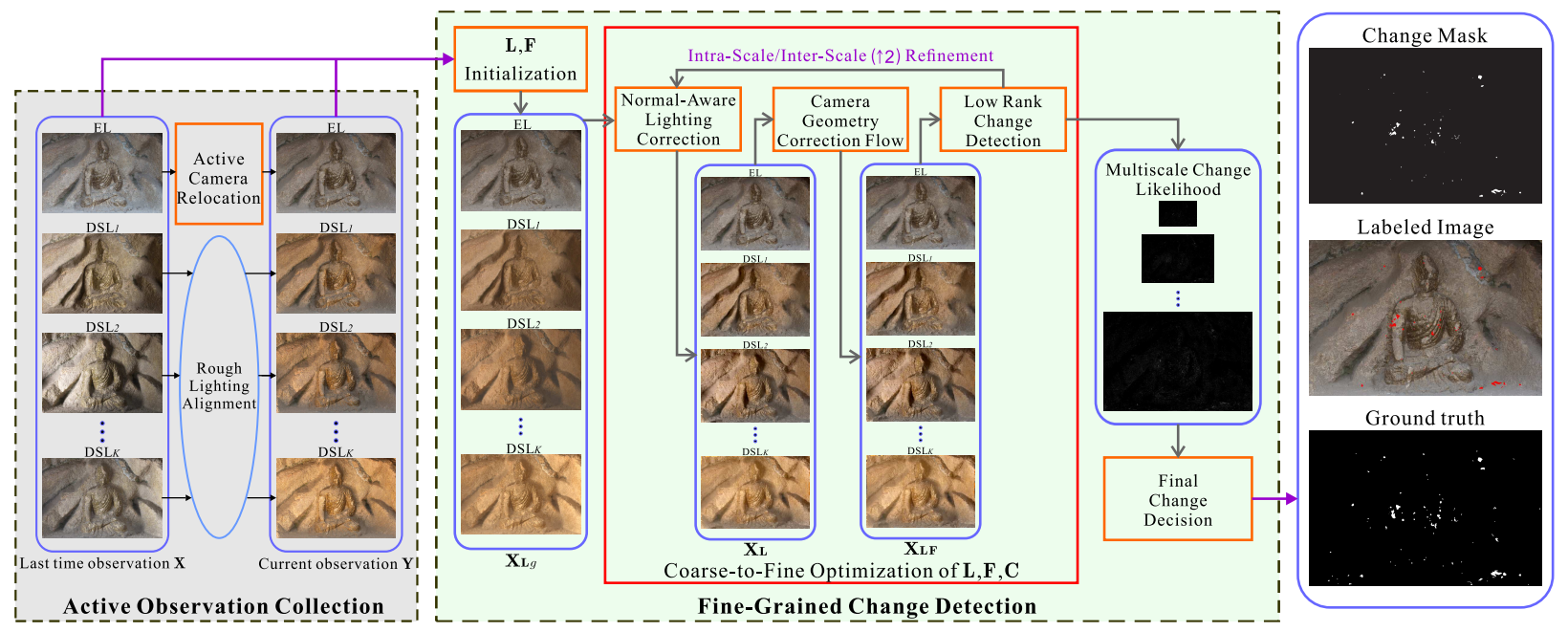
Fine-grained change detection of misaligned scenes with varied illuminations
Wei Feng*, Fei-Peng Tian, Qian Zhang, Nan Zhang, Liang Wan, Jizhou Sun
Content-related spatial regularization for visual object tracking
Ruize Han†, Qing Guo†, Wei Feng*
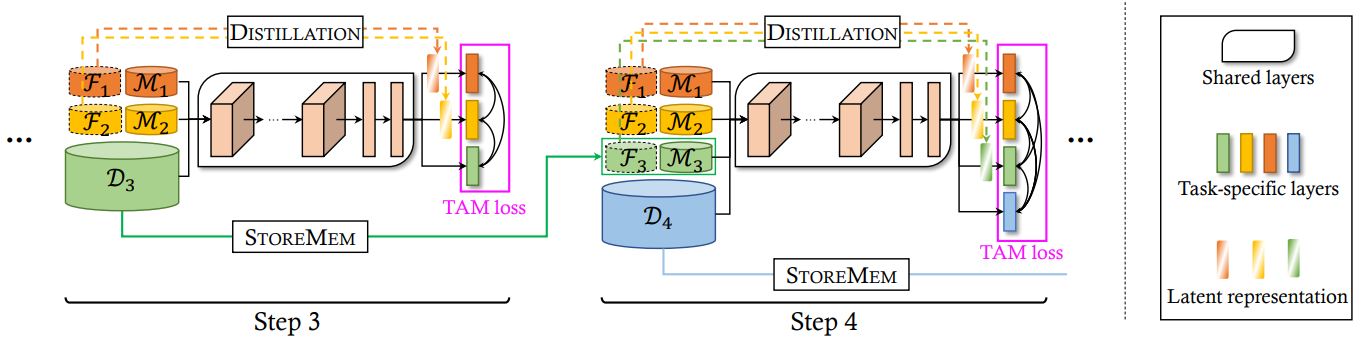
Multi-Domain Multi-Task Rehearsal for Lifelong Learning
Fan Lyu, Shuai Wang, Wei Feng*, Zihan Ye, Fuyuan Hu, Song Wang
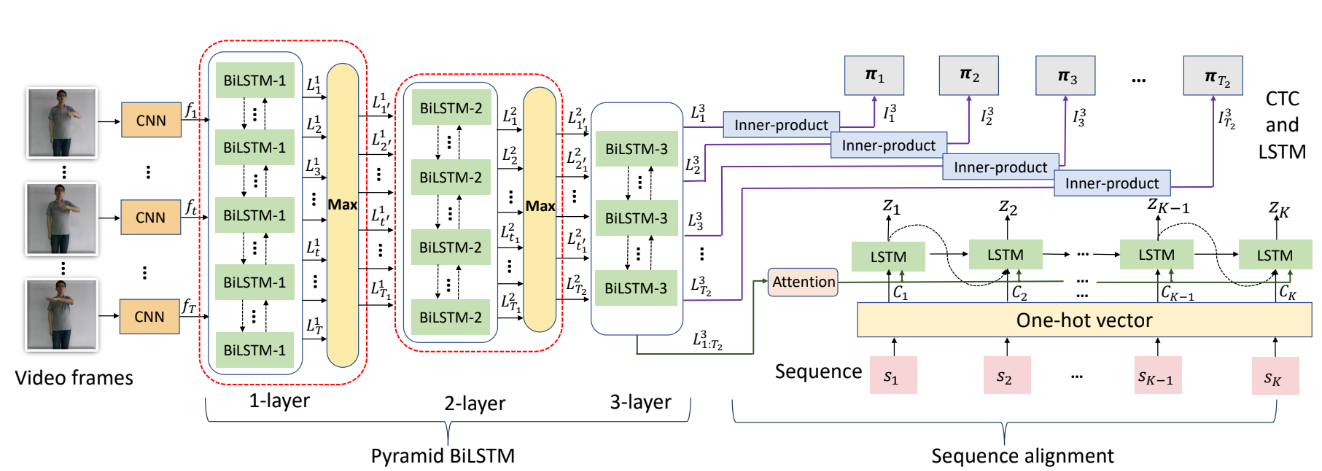
Key action and joint CTC-attention based sign language recognition
Haibo Li, Liqing Gao, Ruize Han, Liang Wan, Wei Feng*
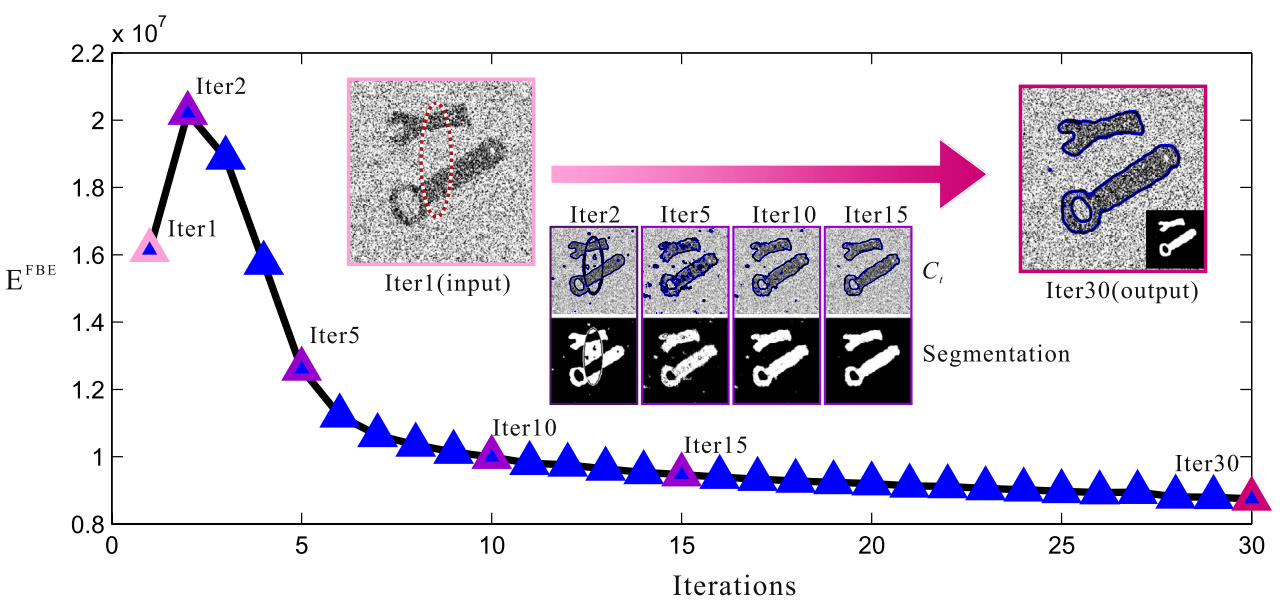
Frequency-tuned active contour model
Qing Guo, Shuifa Sun, Xuhong Ren, Fangmin Dong, Bruce Zhi Gao, Wei Feng*
2025
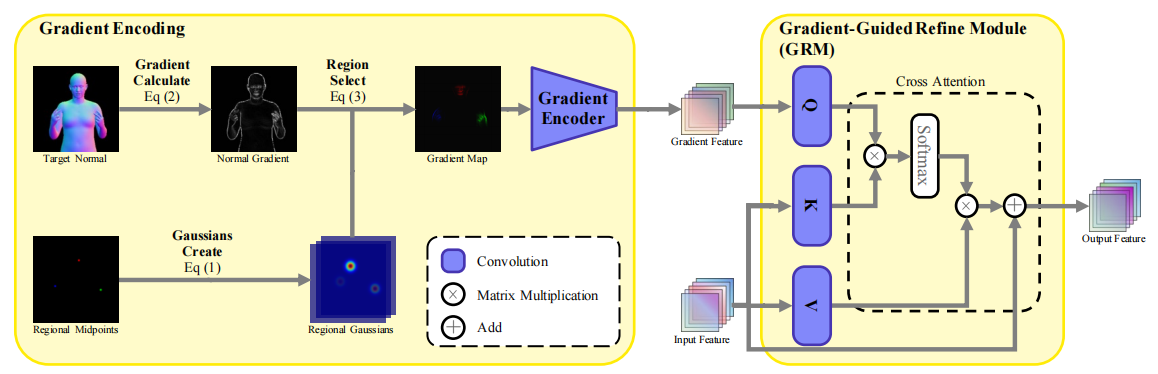
GReg: Geometry-aware region refinement for sign language video generation
Tongkai Shi, Lianyu Hu, Fanhua Shang, Liqing Gao, Wei Feng*
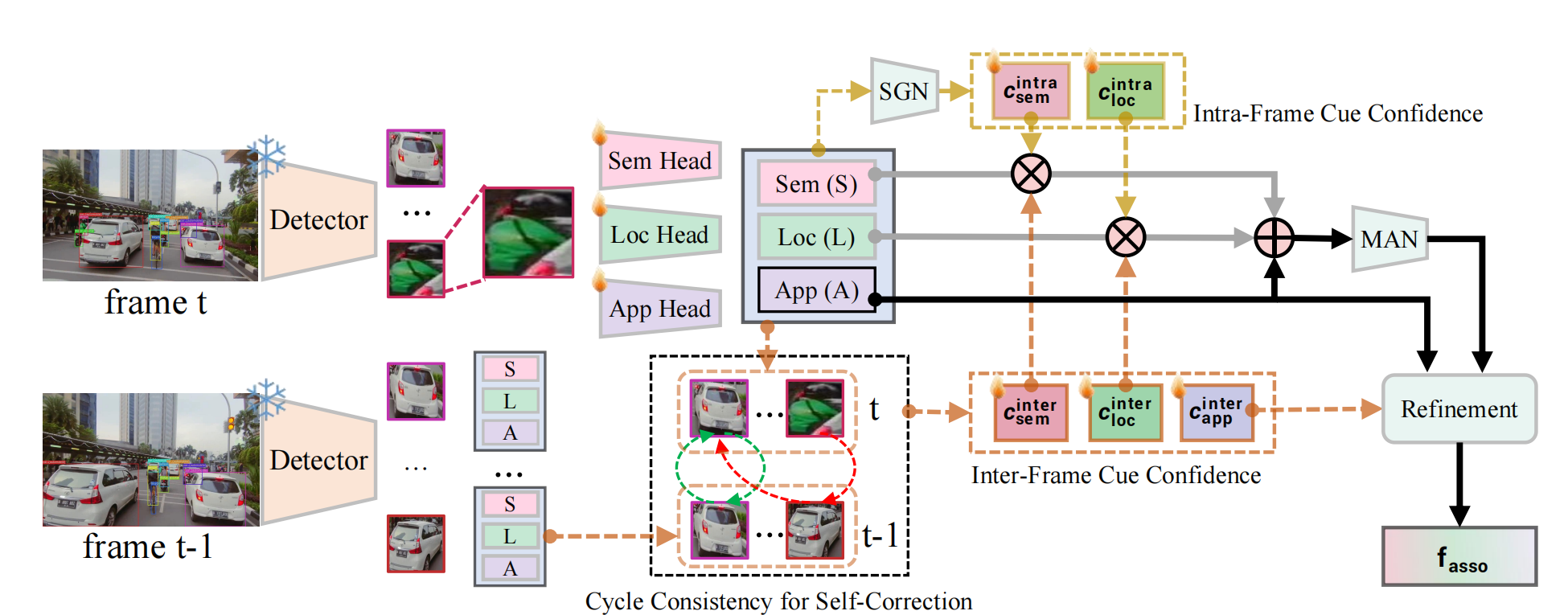
VOVTrack: Exploring the potentiality in raw videos for open-vocabulary multi-object tracking
Zekun Qian, Ruize Han, Junhui Hou, Linqi Song, Wei Feng*
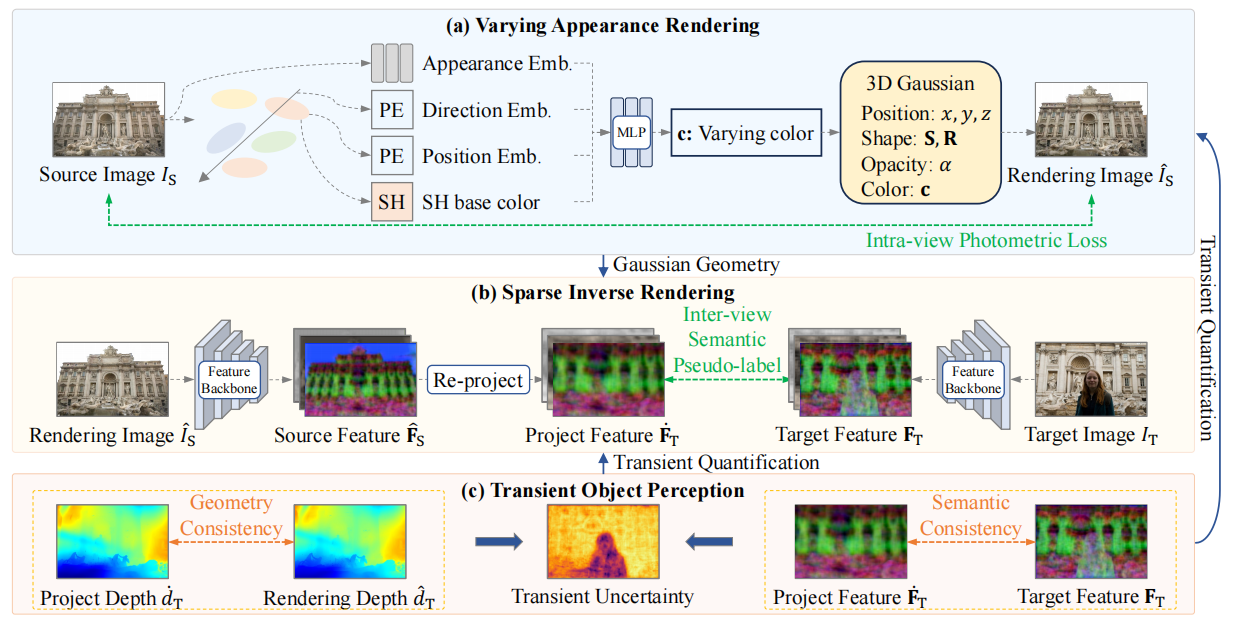
SU-RGS: Relightable 3D gaussian splatting from sparse views under unconstrained illuminations
Qi Zhang, Chi Huang, Qian Zhang, Nan Li, Wei Feng*
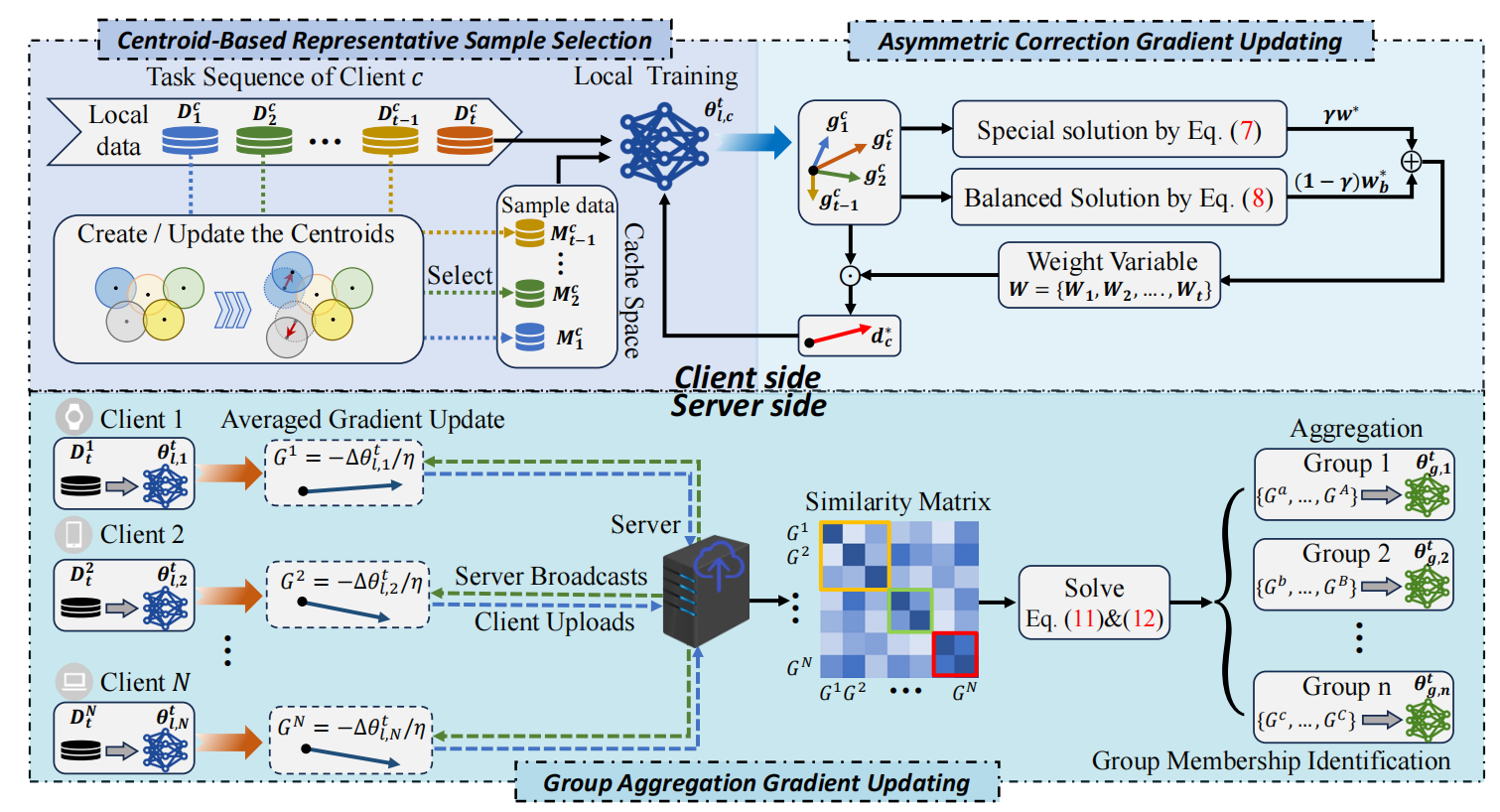
FedAGC: Federated continual learning with asymmetric gradient correction
Chengchao Zhang, Fanhua Shang*, Hongying Liu,Liang Wan, Wei Feng
2024
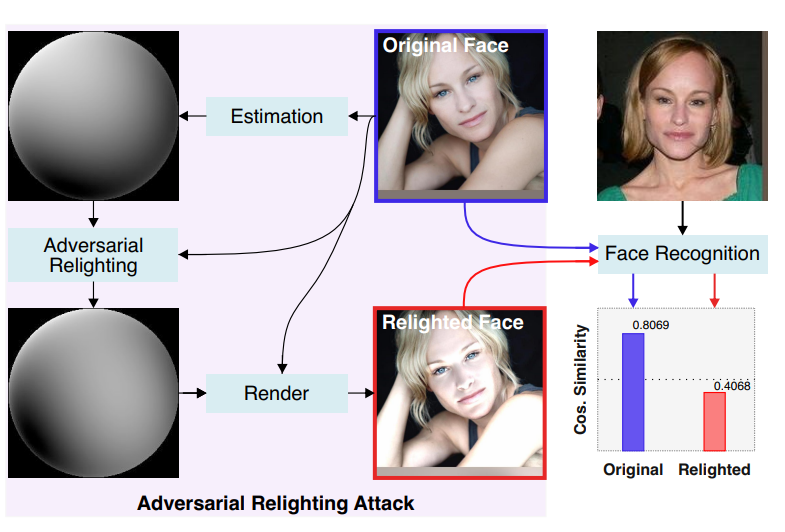
Adversarial relighting against face recognition
Qian Zhang, Qing Guo, Ruijun Gao, Felix Juefei-Xu, Hongkai Yu, Wei Feng*
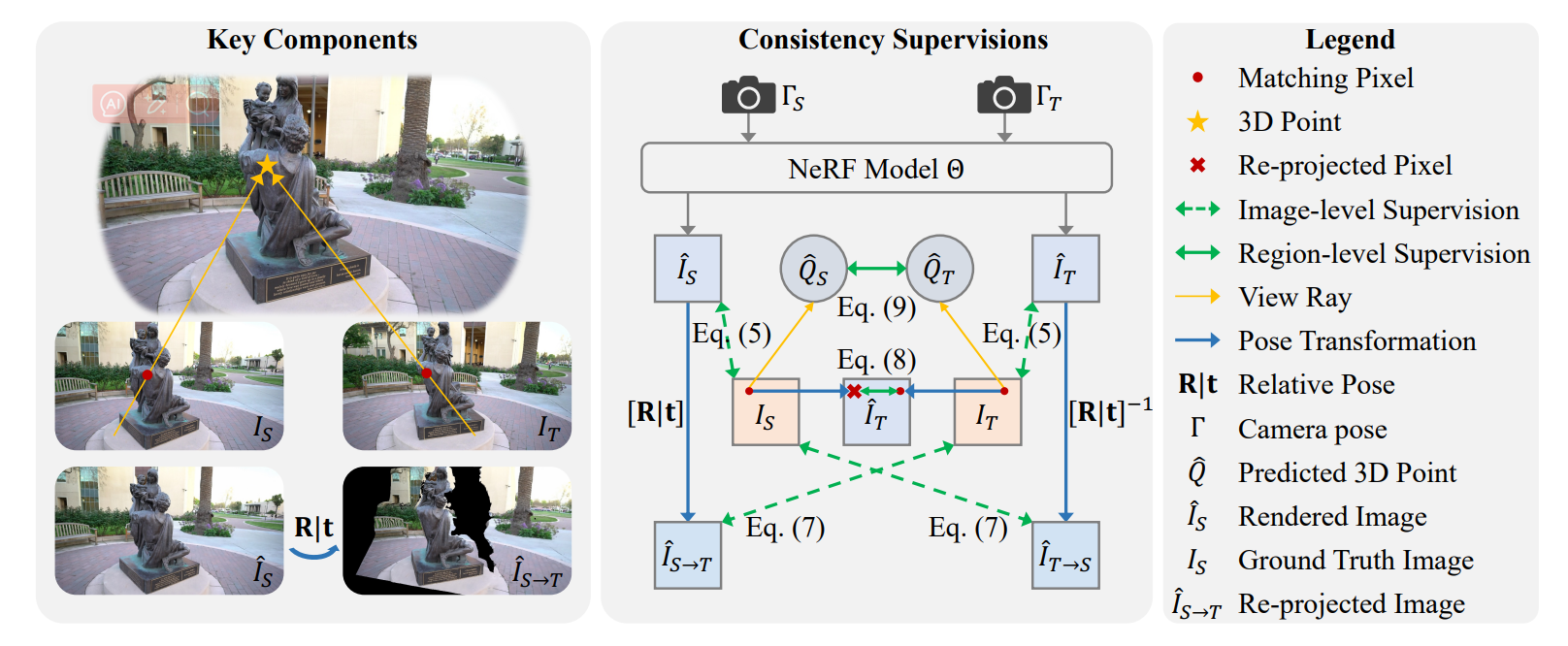
Learning geometry consistent neural radiance fields from sparse and unposed views
Qi Zhang, Chi Huang, Qiang Zhang, Nan Li, Wei Feng*
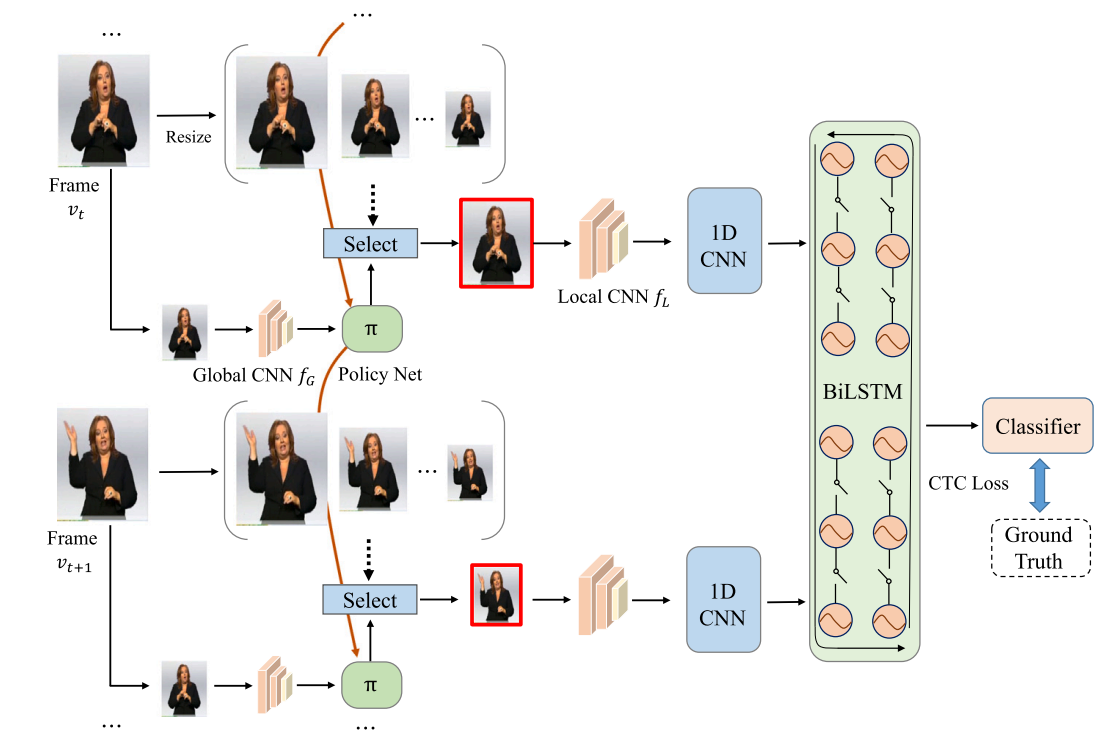
Scalable frame resolution for efficient continuous sign language recognition
Lianyu Hu, Liqing Gao, Zekang Liu, Wei Feng*
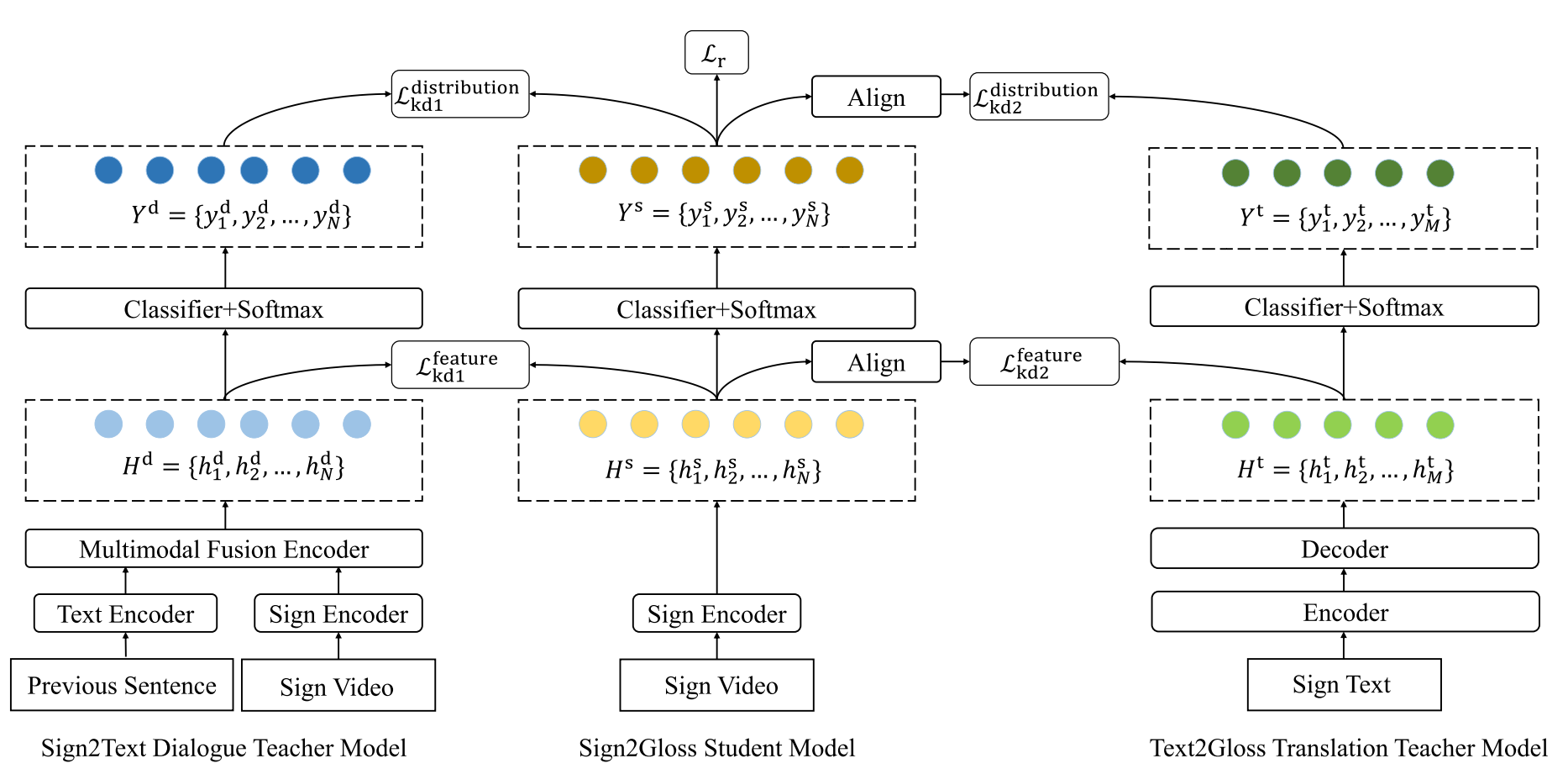
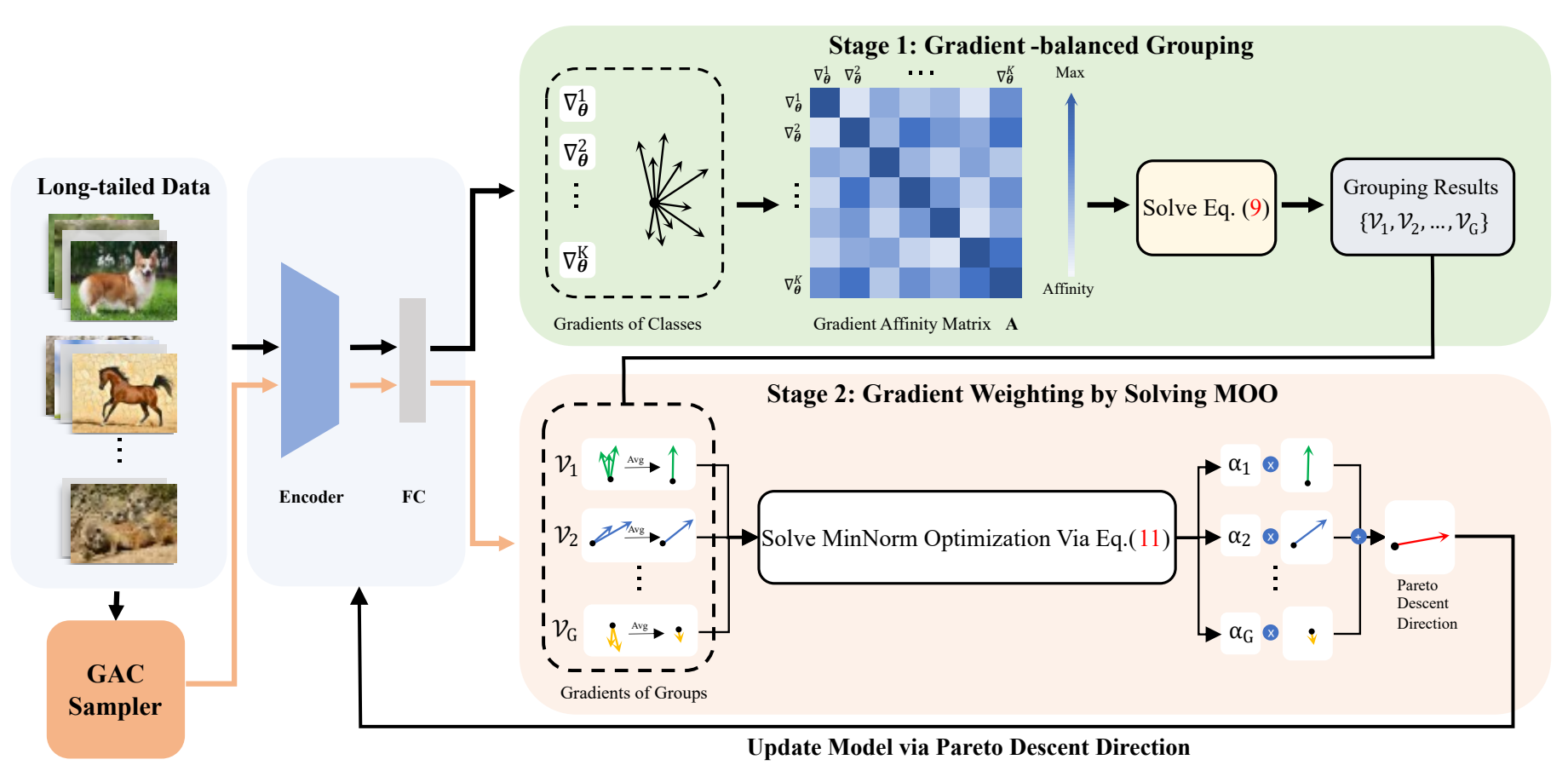
2023

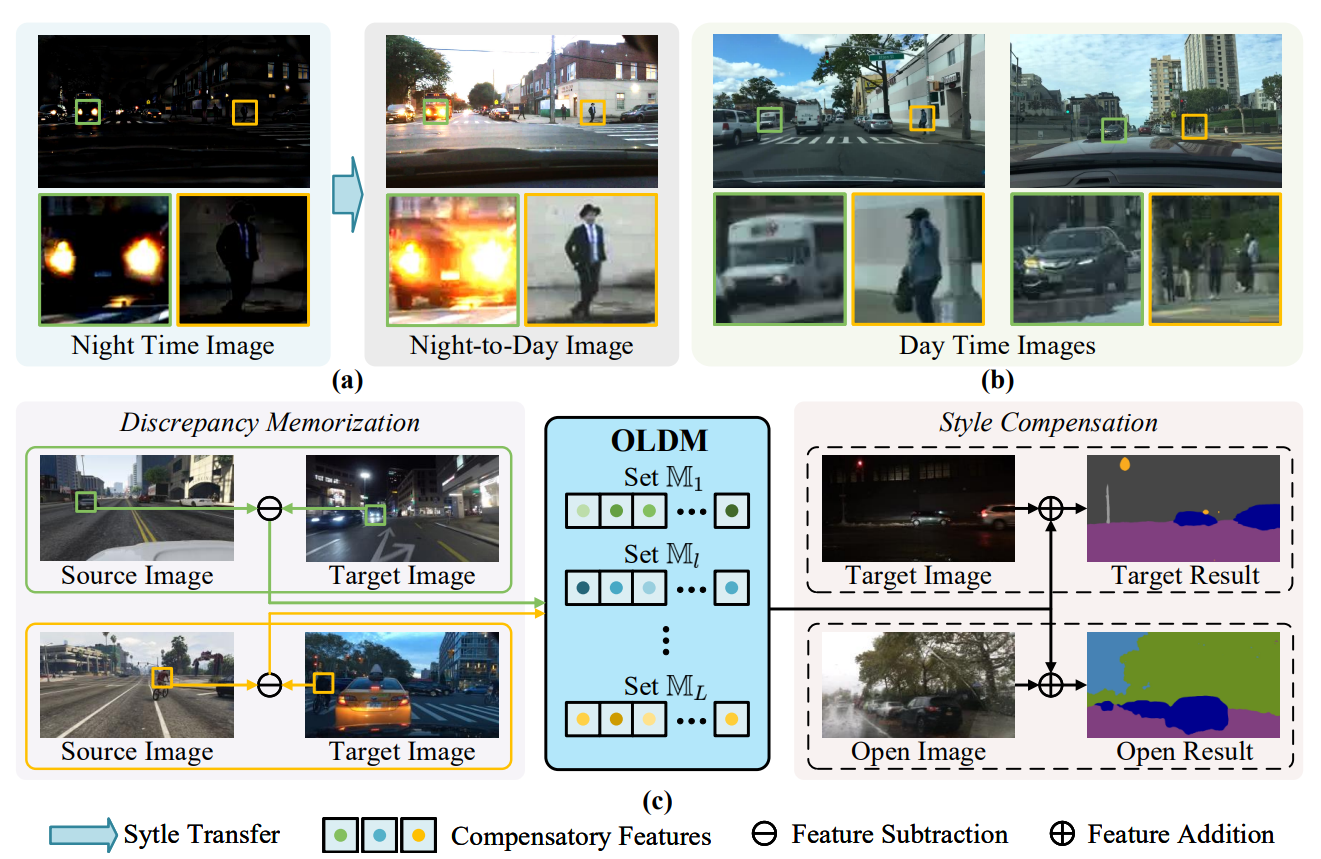
Open compound domain adaptation with object style compensation for semantic segmentation
Tingliang Feng†, Hao Shi†, Xueyang Liu, Wei Feng, Liang Wan, Yanlin Zhou, Di Lin*
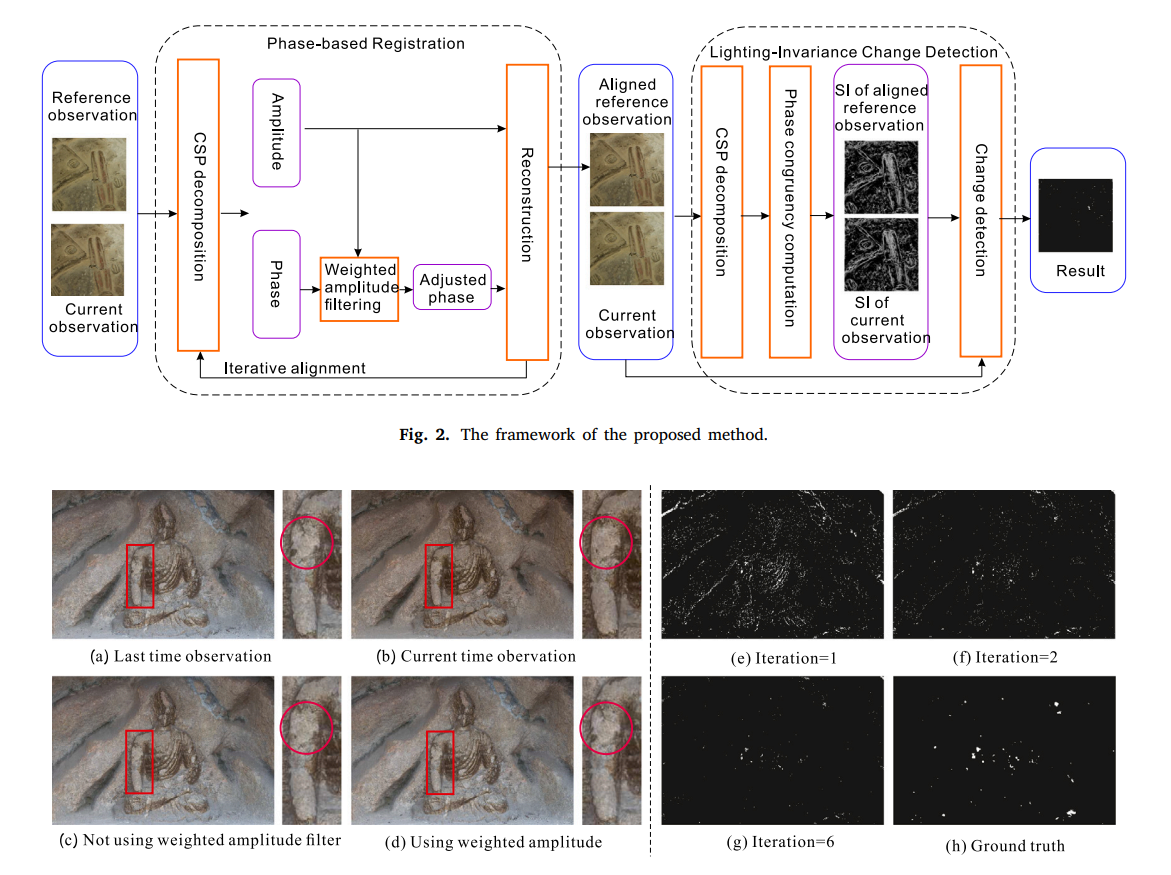
Phase-based fine-grained change detection
Xuzhi Wang, Liang Wan*, Di Lin, Wei Feng