IEEE TPAMI 2025
DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video
Hao Wen1†,
Hongbo Kang1†,
Jian Ma1,
Jing Huang1,
Yuanwang Yang1,
Haozhe Lin2,
Yu-Kun Lai3,
Kun Li1*
1 Tianjin University 2 Tsinghua University 3 Cardiff University
† Equal contribution * Corresponding author
[Arxiv] [Paper] [Supp.] [Code] [Datasets(Coming Soon)]

Abstract
3D reconstruction of dynamic crowds in large scenes has become increasingly important for applications such as city surveillance and crowd analysis. However, current works attempt to reconstruct 3D crowds from a static image, causing a lack of temporal consistency and inability to alleviate the typical impact caused by occlusions. In this paper, we propose DyCrowd, the first framework for spatio-temporally consistent 3D reconstruction of hundreds of individuals' poses, positions and shapes from a large-scene video. We design a coarse-to-fine group-guided motion optimization strategy for occlusion-robust crowd reconstruction in large scenes. To address temporal instability and severe occlusions, we further incorporate a VAE (Variational Autoencoder)-based human motion prior along with a segment-level group-guided optimization. The core of our strategy leverages collective crowd behavior to address long-term dynamic occlusions. By jointly optimizing the motion sequences of individuals with similar motion segments and combining this with the proposed Asynchronous Motion Consistency (AMC) loss, we enable high-quality unoccluded motion segments to guide the motion recovery of occluded ones, ensuring robust and plausible motion recovery even in the presence of temporal desynchronization and rhythmic inconsistencies. Additionally, in order to fill the gap of no existing well-annotated large-scene video dataset, we contribute a virtual benchmark dataset, VirtualCrowd, for evaluating dynamic crowd reconstruction from large-scene videos. Experimental results demonstrate that the proposed method achieves state-of-the-art performance in the large-scene dynamic crowd reconstruction task.
Method
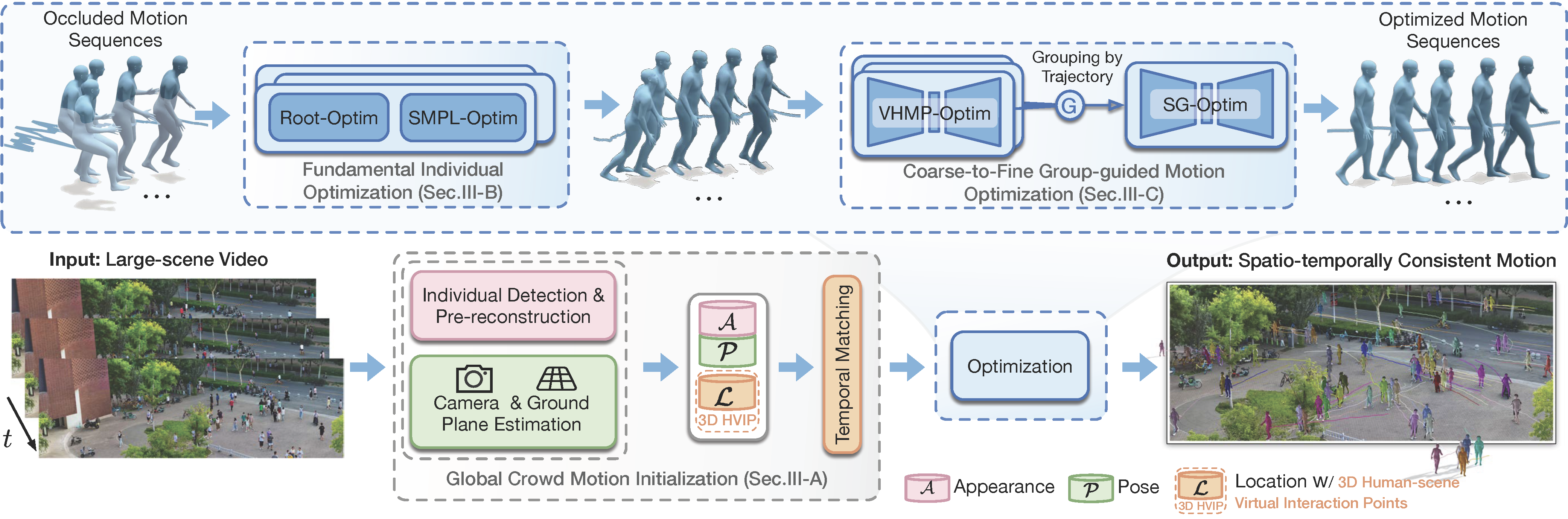
Fig 1. The overview of our framework.
Demo
Proposed Dataset: VirtualCrowd
We construct VirtualCrowd, which includes eight 8K validation videos (60–200 people; 931 sequences; 186,200 poses with 2D/3D annotations) used in the paper, plus two additional simulated sloped-scene videos provided as supplementary data.

Technical Paper

Citation
Hao Wen, Hongbo Kang, Jian Ma, Jing Huang, Yuanwang Yang, Haozhe Lin, Yu-Kun Lai and Kun Li. "DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video". IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025.
@article{wen2025dycrowd,
author = {Hao Wen, Hongbo Kang, Jian Ma, Jing Huang, Yuanwang Yang, Haozhe Lin, Yu-Kun Lai and Kun Li},
title = {DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2025}
}