(通讯员 孙浩然)日前,天津大学自主研发的“伏羲传语”(FuxiTranyu)多语言大模型正式发布并开源。该模型采用了多语言预训练数据均衡策略,以应对大模型在不同语言间的性能差异问题及低资源语言性能低的挑战。模型完全从头开始训练,研发团队完成了大规模多语言数据的收集和处理、8B基座模型预训练、指令对齐训练及多语言基准测评全过程。

arXiv:https://arxiv.org/abs/2408.06273
HuggingFace: https://huggingface.co/TJUNLP/FuxiTranyu-8B
GitHub:https://github.com/tjunlp-lab/FuxiTranyu
伏羲传语大模型支持“一带一路”沿线、亚洲及欧洲多个国家的官方语言,合计43种,包括汉语、英语、阿拉伯语、葡萄牙语等富资源语言,以及孟加拉语、缅甸语、泰米尔语等低资源语言,覆盖汉藏语系、印欧语系、亚非语系等10大语系。除此之外,伏羲传语还支持C++、Java、C、C#、Python等16种编程语言。预训练数据来源涵盖互联网、书籍、论文、百科、代码数据。此次预训练使用了研发团队收集的28万亿词元数据中的6060亿词元数据。
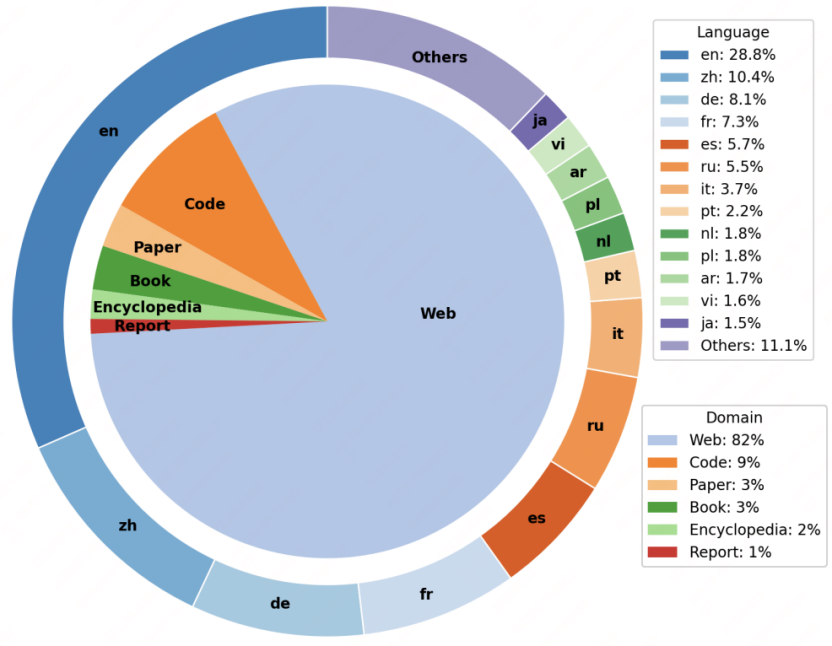
图1 伏羲传语多语言数据及数据来源分布图
除了基座模型FuxiTranyu-8B,伏羲传语还推出了两个指令微调模型:FuxiTranyu-8B-SFT及FuxiTranyu-8B-DPO。前者在多样化的多语言指令数据集上进行了有监督指令微调,后者则在人类偏好数据集上通过DPO技术进一步增强了模型的对齐能力。相比基座模型,指令微调模型在多语言能力、对齐能力上得到了显著的提升,能够更好地遵循人类指令,生成的回复更符合人类价值观。

表1 伏羲传语预训练及后训练主要参数设置
在多项多语言基准测试中,与已开源的多语言大模型BLOOM-7B、PolyLM-13B、Llama-2-Chat-7B、Mistral-7B-Instruct-v0.1相比,伏羲传语展现出强大的竞争力。在多个广泛使用的判别基准评测任务上,基座模型FuxiTranyu-8B明显优于BLOOM-7B和PolyLM-13B等多语言模型,指令微调模型则在XCOPA上取得了最佳效果,并在m-Hellaswag、XWinograd和XStoryCloze数据集上,显著优于Llama-2-Chat-7B和Mistral-7B-Instruct-v0.1。在摘要生成任务上,伏羲传语优于所有对比的基线模型。
m-ARC (25-shot) |
m-HellaSwag (10-shot) |
m-MMLU (5-shot) |
XWinograd (5-shot) |
XCOPA (0-shot) |
XStoryCloze (0-shot) |
|
Llama-2-7B |
35.5 |
48.6 |
35.4 |
78.0 |
58.9 |
55.6 |
Mistral-7B-v0.1 |
40.7 |
54.5 |
46.7 |
80.5 |
55.8 |
60.2 |
BLOOM-7B1 |
31.8 |
43.4 |
27.1 |
70.0 |
56.9 |
58.2 |
PolyLM-13B |
30.6 |
46.0 |
26.4 |
73.4 |
58.9 |
56.4 |
LLaMAX2-7B |
33.1 |
50.3 |
26.7 |
76.9 |
54.5 |
58.8 |
FuxiTranyu-8B |
32.7 |
51.8 |
26.6 |
76.1 |
60.5 |
58.9 |
表2 基座模型测评
Models |
m-ARC (25-shot) |
m-HellaSwag (10-shot) |
m-MMLU (5-shot) |
XWinograd (5-shot) |
XCOPA (0-shot) |
XStoryCloze (0-shot) |
Translation (0-shot) |
Summarization (0-shot) |
Llama-2-Chat-7B |
36.4 |
46.3 |
36.0 |
74.8 |
55.9 |
56.5 |
22.1 |
4.6 |
Mistral-7B-Inst-v0.1 |
36.3 |
45.5 |
39.0 |
74.0 |
54.5 |
53.4 |
19.1 |
2.2 |
BLOOMZ-7B1 |
31.2 |
38.0 |
25.8 |
64.0 |
53.3 |
49.8 |
14.7 |
4.4 |
PolyLM-MultiAlpaca-13B |
28.6 |
39.1 |
25.9 |
70.9 |
59.9 |
57.0 |
- |
- |
LLaMAX2-Alpaca-7B |
38.7 |
52.5 |
35.4 |
77.4 |
56.6 |
62.0 |
29.1 |
0.3 |
FuxiTranyu-8B-SFT |
31.8 |
51.5 |
26.8 |
75.7 |
61.3 |
56.6 |
25.9 |
8.9 |
FuxiTranyu-8B-DPO |
32.8 |
52.2 |
27.3 |
74.1 |
62.1 |
56.9 |
26.4 |
7.3 |
表3 指令微调模型测评
研发团队进一步对伏羲传语、BLOOM等多语言大模型进行了深入分析和对比。基于神经元和表征层面的可解释性分析结果表明,相比于BLOOM,伏羲传语具有更好的多语言均衡学习能力。
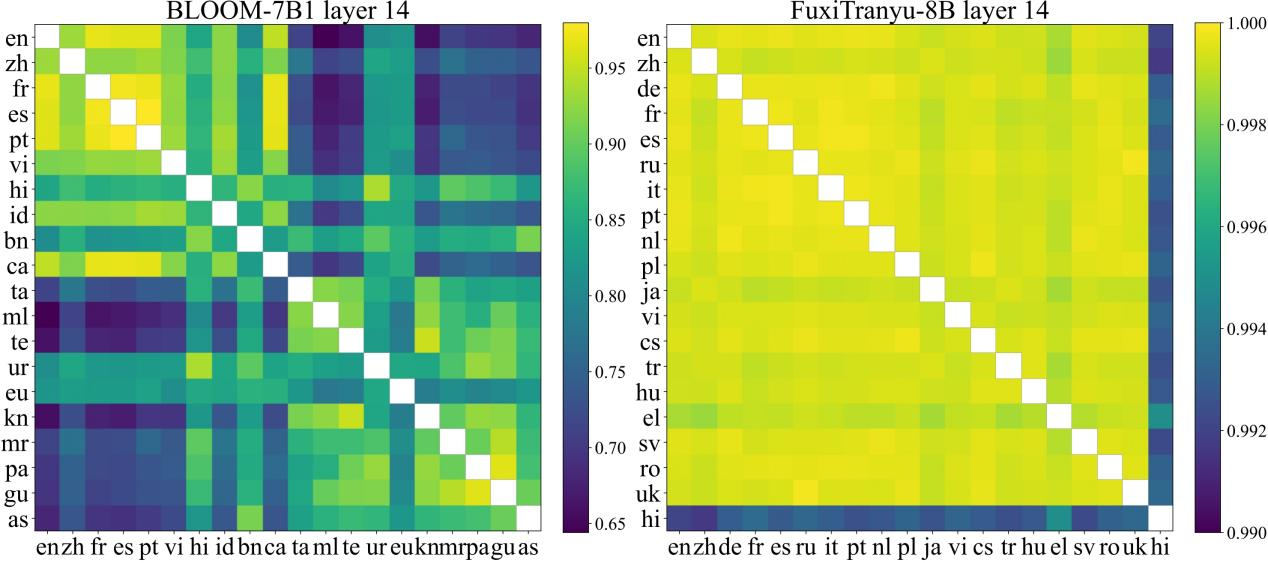
图2 FuxiTranyu与BLOOM多语言学习内部表征相似性
为了进一步推进多语言大模型的研究与应用,研发团队已将伏羲传语基座模型、指令微调模型及58个预训练检查点在 HuggingFace平台上开源。
